vch 117r ewche 117r vch 122r ewche 123v
2.2.3 Sampling and analysis of scribal outputs
Each separate profile represents the language of a single scribal text. A scribal text is here to be understood as any consecutive written output that is a single text in the literary sense, or a part of such a text, and written by a single scribe. So a scribe who copied, say, the Prick of Conscience and then Rolle’s Form of Living, would provide at least two scribal texts; and were separate samples taken from the Prick of Conscience, say Book II and Book IV, then these would count as separate scribal texts, even though they belong to the same literary text. In the same way, two separate copies of the Prick of Conscience, each written by a different scribe, would count as two scribal texts; or if a single copy of the Prick of Conscience consisted of the scribal stints of two different scribes it would also count as two scribal texts.
For reasons that will become apparent in chapter 3, the analysis must be consecutive for each scribal text considered: the linguistic environment in which a given form appears is crucial to the whole analysis. The analysis should also be exhaustive, at least in principle; in practice it is possible to reduce the labour somewhat, by closing the entry for an abundantly attested item at some specified and duly noted point of the scribal text being analysed––but without due annotation, it is thoroughly misleading to continue entering unusual forms for an item after closing the entry for a well-established equivalent, because in such a record the relative frequencies of functional equivalents could be seriously distorted. When the scribal output is very large, and comprises but a single literary text, it may with advantage be broken into a series of separate scribal texts, each of manageable size but representing nevertheless a significant sample. The samples themselves need not account for the whole output, but may with advantage be spaced at intervals, e.g. five consecutive folios from the beginning, five from the middle, and five from the end. These profiles, especially if the samples are short, can be unordered, or only partially ordered, without loss. Given a series of such profiles, based on the exhaustive analysis of sample scribal texts, something may be said about the linguistic structure of the whole, and about the scribal dialect in particular. A blanket analysis for the entire literary text, in which the forms entered under (say) ‘after’ are drawn mainly from the beginning of the text, but those for (say) ‘each’ are taken from the end, is worth nothing at all.
2.2.4 The detection of linguistically composite texts
If the profiles for these samples are linguistically identical, they are then merged as a single profile which, pending further test (see 3.5.4–5 below), is taken as the homogeneous usage of a single scribe. If, as is very commonly the case, they differ, then further analysis is undertaken with the aim of finding where and in what manner the language changes. The forms that do change between samples are already known, and analysis can be selective, concentrating on just a few items. Samples can be taken so as to ‘zero in’ most efficiently on the place where the language changes, by working inwards from the fully-analysed stretches either side of an unanalysed gap. The first such sample is taken midway between the analysed stretches, and subsequent samples midway between what emerge as linguistically dissimilar parts of the text. The intervals become progressively smaller and, if the change is abrupt, it can be precisely defined. The constituent profiles must henceforth be treated separately, each being assessed for the validity of its status as homogeneous dialect material. The question of composite texts is considered in greater detail in 3.3.1–5 below. A partial account of the dialectal stages in the transmission of a text is not of course a substitute for a stemma, and in principle it is independent of textual relations; but they cohere sufficiently often for the one to pose worthwhile questions in respect of the other, and as Professor Samuels has shown for the Piers Plowman manuscripts, dialectal groupings may in some cases be the more revealing. (See further 4.1.4.)
2.3 Constructing the dialect map
2.3.1 The mediaeval and modern data compared
When one is compiling a modern linguistic atlas, it is a relatively simple matter to establish the places of birth and upbringing for almost any living informant, and the dialect of any inhabited area can be recorded by sending a competent field-worker there. One starts with known places and proceeds to select informants and elicit data from them, the aim being to discover and present cartographically the patterns displayed by those data. In the case of Middle English, on the other hand, all the data available are what are preserved in manuscripts, and there is no chance of eliciting more. The informants, moreover, are much more elusive; Middle English scribes are self-effacing and for the most part anonymous, and only exceptionally do those who copied literary manuscripts tell us anything directly about where they were living or were brought up. It is rather as if the compilers of a modern dialect atlas had access to any number of speakers, all willing to be interviewed, but very few of whom divulged where they came from. Therefore, the greatest problem confronting a dialectologist working in Middle English is to determine the provenance of most of his informants, and this indeed throughout the investigation is his main task. For, unless this is achieved, it is not possible fully to realise the other aim, that of elucidating the geographical distributions of the material.
2.3.2 ‘Anchor’ texts
The starting-point of any dialectal investigation of mediaeval English must be with texts that can be associated with definite places or areas on non-linguistic grounds. It is essential to begin by plotting on maps all the material that can be derived from such sources: these are the ‘anchor’ texts which attach the whole structure to the real topography of Britain.
Local documents constitute the one large body of texts whose origins are in most cases either explicit or readily deducible. ‘Local documents’ is, of course, merely a convenient label for a quantity of texts of very diverse origins, such as personal correspondence, the records of manors and municipalities, the records of courts, secular or ecclesiastical (though the latter are commonly in Latin), and legal instruments––depositions and indentures, conveyances and arbitrations. Most of these can be expected to contain indications of their local origins, and in general they can be trusted to attest a form of the written language, if not precisely of the stated place, then of somewhere near to it. There are exceptions, and in due course these can be recognised as the work of scribes whose habits of written language were acquired at a greater or lesser distance from the places to which the documents themselves relate. The principles by which scribal dialects can be assigned to different areas on linguistic grounds alone are discussed below (2.3.3 seq.).
Nevertheless, however essential local documents may be as a foundation for a dialect survey, the fact remains that they are totally inadequate in their provision of the main material of which it must consist (1.3.1). For one thing, their coverage of the country is uneven, e.g. there are far more for Lancashire than for Wiltshire. But their main disadvantage is sparseness of lexical range. In legal texts, for example, though certain words can be almost guaranteed to appear (the, this, that, of, have, (afore)said, hold, given, between, witness, year(ly), etc.), others occur rarely: e.g. she, those, though, earth, world, eye, fire, fruit. For various reasons, these latter and many other such are of particular philological interest. On the basis of local documents alone, therefore, our maps would give only a thin and patchy coverage for a quite restricted number of items. This brings us to a central problem: only the literary works can provide us with anything approaching an adequate sample of the language, but unless the literary manuscripts are localised, how can one utilise the linguistic information in them?
2.3.3 The ‘fit’ technique: preliminaries
There is in fact a way that we can utilise more manuscripts than those which have been localised on non-linguistic grounds; the literary manuscripts can be incorporated into the matrix created by mapping of the anchor texts. This process we call the ‘fit’ technique. The importance of local documents relates only in part to the material they contribute directly; their special value is that they offer a means of localising literary manuscripts.
The principles of the ‘fit’ technique are as follows. From dialect atlases of modern languages, it emerges that regional (spoken) dialect is characterised by a non-random, orderly patterning over space (the ‘dialect continuum’: cf. 1.2.2). There are good grounds prima facie for believing that the written dialects of Middle English behave similarly: firstly they can be assumed to have corresponded, at least to some degree, with spoken dialects (this correspondence, of course, only being realisable in the three categories which have correlates in spoken language: cf. 2.1.1); secondly, the great diversity of the written language, as a cultural phenomenon, presents per se a strong case for correlations. For Middle English, therefore, it is to be expected that a given regional dialect (a particular cluster or combination of linguistic features whether spoken or written) can only be ‘placed’ in a relatively restricted area of the dialect map of the whole country.
Suppose, to take an example from the modern language, we encountered a speaker who said min for ‘man’ and far for ‘where’. If we had a dialect atlas containing maps for ‘man’ and ‘where’, we could discover the linguistic origins of our speaker. We could cross out all those parts of the map for ‘man’ in which min was not recorded. Similarly, we could cross out all those parts of the map for ‘where’ in which far did not appear. The remaining area, free of crosshatching, would be the provenance of our speaker. The more characteristics of his speech we took into account, the more narrowly would the area be restricted; with each successive crossing-out, the blacker would appear those areas to which it was least likely that the speaker belonged. This indicates the importance of using as many different criteria as is feasible (cf. 1.2.2), and the prime diagnostic value of assessing items in combination.
Experiment with Scots material from the Linguistic Survey of Scotland in 1953 demonstrated the validity of this method. Information from written responses to questionnaires was examined, the provenance of those responses being withheld from the investigator for the purposes of the experiment. Attempts were then made to establish the provenance by finding where on the map the forms they contained squared with those which had already been entered in their correct location from other questionnaires. It was found that by a process of elimination the totality of dialectal characteristics of each informant could be assigned uniquely to one relatively small area. The actual place of origin of an informant was always found to lie within it. Furthermore, these characteristics could not be placed where they did not belong. Thus, the technique has proved to be a reliable discovery procedure.
The same ‘fit’ technique can be used for localising hitherto unplaced Middle English manuscripts. The analysis of a completed questionnaire yields a linguistic profile of the given scribal dialect. Each form in the linguistic profile can be assessed in relation to the relevant base map for the item to which it belongs. Every time this is done a different part of the country will be excluded from further consideration. Step by step, the eligible area is reduced and converges on that part of the country where the distributions of individual items overlap. The production of base maps is not therefore an end in itself; the maps are an indispensable research-tool. Every new scribal dialect thereafter fitted into the matrix they furnish then provides an additional fixed point, thus increasing our knowledge of the distribution of dialectal features, and facilitating the placing of yet further texts (McIntosh 1963).
2.3.4 The ‘fit’ technique: some details of its application
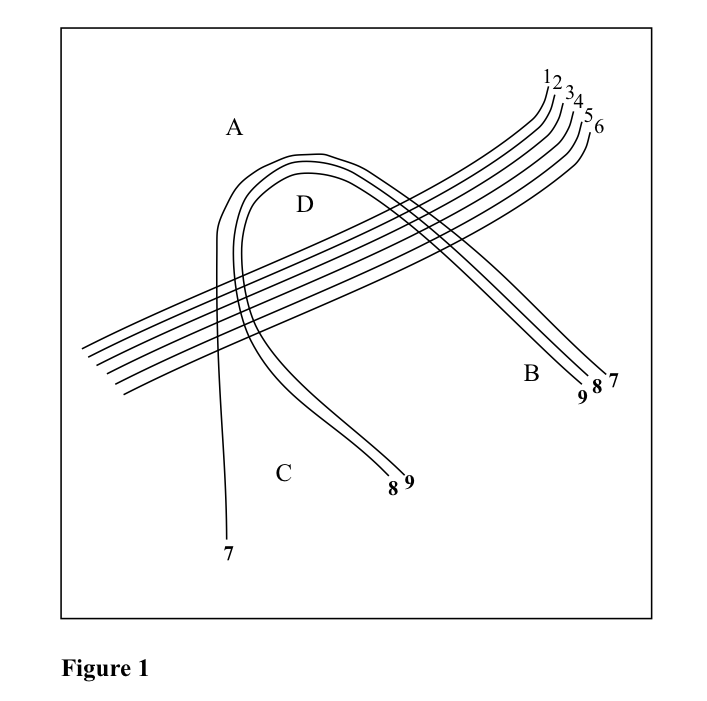
The incorporation of new, hitherto unlocalised texts into the matrix presents problems of varying complexity. If the operation were carried out in simple linear terms, it would not be difficult, given two localised texts A and B, to place a series C, D... in probable order between them. But since one is dealing with an area, not a line, the least one can feasibly operate with is a triangle of localised texts, say A, B and C, within which one may then confidently place a fourth text D. In that simple situation, with only one new text to place in the triangle, the next question to arise is whether D is to be placed nearer to A, B or C. Here it seems reasonable to assume that if D agrees with A for more items than with B and C, it belongs nearer to A in space; but one could not prove this absolutely since there are no means of knowing whether an area marked by a majority of A-type forms did not run almost to the threshold of B and C. In this position one has to judge by the quantity and relative importance of the items involved, and also by some assessment (from other localised texts outside the triangle) of the directions in which the boundaries of the various distributions are likely to have run. A typical dilemma is shown in Figures 1 and 2.
In Figure 1, the placing of D close to A is made on the assumption that the distributions for items 1 to 6 are bounded by a line running directly from north-east to south-west, but it involves some seemingly less probable skewing of the distributions for items 7, 8 and 9. There may, of course, be perfectly good reasons for such skewing, if A is located at some cultural centre to which new forms for items 7–9 might be likely to spread. But failing evidence to that effect, a placing as in Figure 2, which involves less skewing overall, may seem preferable.



At a later stage, having placed two further texts E and F within the same triangle, one might encounter a new text G, also apparently from the same area, but posing the problem that for some items it appears to require a placing west of F whereas for others it requires a placing east of E (Figure 3).
Text G thus carries new information which enables us to refine our placing of these texts. It shows that the previous placing of E and F was slightly inaccurate, and that a rearrangement as shown in Figure 4 is the only one that will satisfy both the earlier and the new information.
2.3.5 A qualification: ‘Border-areas’
The example just given is of a configuration in which all the distributional boundaries were clear-cut, and where a re-arrangement proved feasible nevertheless. However, this is not always the case. It often happens that no rearrangement is possible because, although all the texts in question are consistently written and clearly belong in the same area, the new text, wherever placed, will for one or more items contravene the existing boundaries and have to be accommodated in a small separate enclave slightly outside the main distribution for that item. Now, although such enclaves are perfectly possible, one has at this point to consider whether that boundary is really as clear-cut as has hitherto been assumed.
Boundaries between forms (‘isoglosses’) are of two kinds:
(ii) There is an overlap of the two areas of occurrence, so that the area of division between them must be represented by a mixed belt or ‘border-area’ in which both forms are found in free or conditioned variation. An example of apparently free variation is the co-occurrence of er and or ‘ere’ (conj.); an example of conditioned variation is the co-occurrence, as a minor system, of þem ‘them’ as the stressed form alternating with hem as the unstressed form (cf. Samuels 1981, p. 46).
One of the findings of modern dialectology is that, in the dialect continuum, every area is, in respect of some of its features, a border-area. This means that in all configurations the investigator may, if only for a few items, consider the possibility of an overlap of two forms for the same item, either co-occurring in a single text or occurring separately in two neighbouring and otherwise similar texts. Naturally, if a text is encountered that demands the assumption of an abnormally large number of border-areas, the suspicion must be that it is a mixture of some sort, though that is not necessarily the case (cf. 3.1, and chapter 3, passim, for the various possible kinds of mixture).
The size and shape of border-areas can be judged only after the investigation has proceeded some way, and there are then three possibilities:
(b) if the other texts show some, but less, resemblance, it is likely to be a shallower but longer belt;
(c) if the other texts show little or no resemblance, the variation is to be regarded as a merely sporadic feature occurring at separate points of the same boundary, or of other, non-contiguous boundaries of the same feature.
2.3.6 Some conclusions on the ‘fit’ technique
As shown in the preceding sections, some applications of the technique are straightforward, but in others, decisions may be needed on whether to assume skewed distributions or, if the evidence permits, border-areas for one or more items. But whichever decisions may be taken in individual cases, they do not affect the overall conclusion: that although the localisations have to be approximate at first, the resultant configuration is inherently self-refining. As the matrix fills up, so the room for manoeuvre is reduced, and with it the degree of indeterminacy. It does not matter too much if the absolute position of many of the texts is uncertain; it is important however that their position relative to one another is schematically sound. The denser the entries on the maps become, the closer we may hope to come to the correct absolute position for each text. For some areas, where source materials are relatively abundant (for example, the south-west Midlands), the coverage is such that the placings given in this Atlas are probably accurate to within ten miles; in other areas, like Devon and north-west Yorkshire, we cannot always be confident that our relative placings are correct to within three or four times that distance.
The developing pattern will appear to be in error just as soon as it fails to accommodate some internally consistent scribal language that seems to have as good a claim as any other to be regarded as genuinely local. It is significant that such misfits have generally turned out to be of Hiberno-English provenance; that is, they turn out to belong to a different, but related, continuum.
2.3.7 A mapping problem
Details concerning the entry of forms on maps are given in volume II, pp. xi–xiii, but there is one problem that may be mentioned here. Normally the fitting of texts in the matrix is straightforward provided that they remain fairly evenly spaced, and if in some areas the entries become very dense one selects for entry those texts that yield most additional information. However, in the case of cities and cultural centres this question of selection poses a problem. The rate of linguistic change is faster in cities than in rural areas, and is typically manifested by the replacement of one dialect ‘type’ (say, one that is similar to those south of the city) by another that is similar to dialects lying (say) north-east or north-west of the city.
In such cases there can be no question of making a selection, and both types must be represented. But since the maps cannot be three-dimensional, one has to choose between (a) simply listing the texts by number, or (b) placing them at those points around the city where their features appear to agree best with those of the surrounding dialects and therefore, cartographically at least, form a unity with them. We rarely have the evidence to tell whether (b) has any historical or geographical validity, but it is certainly no more arbitrary than (a), and often more convenient. The most obvious, but also the most problematic, case of its application is the London area, where the earlier texts are placed east and north-east of the city centre, the later ones centrally or north and north-west of the centre. These placings are convenient for representing the great majority of items, but there are occasional reminders (notably the south-eastern hy ‘she’) that the ideal would have been a three-dimensional map in which such replacements were represented vertically.
Chapter 3 SCRIBAL AND OTHER MIXTURES
3.1 Dialectal reliability
3.1.1 The assessment of consistency
As was emphasised in 1.3, there is undoubtedly a large body of consistently translated but hitherto unlocalised texts which, when localised by the ‘fit’ technique, must provide the basis for any widening of our knowledge of the subject. The method of identifying a consistently written text is careful analysis by questionnaire (2.2); and the main criterion for judging that consistency is that it should not show (a) combinations of forms for the same item that are clearly incompatible because they are expected only in widely separated areas, or (b) variation for an abnormal number of items (cf. 2.3.5). The definition of ‘abnormal’ in (b) is slightly complicated by the fact that a few areas of the country that are crossed by a high proportion of isoglosses (the traditional ‘bundles’, cf. 1.2) can be expected to show variation for more items than elsewhere. Our main criterion for judging texts from these areas must be the ‘fit’ technique itself: they must, when placed, show no recalcitrant features that are at odds with those of neighbouring texts. The same test––whether a text will fit the matrix ––may be expected to show up any text containing an incompatible mixture of forms of type (a) above.
Hitherto, it has throughout been assumed that major scribal mixtures can be detected and identified; but the question of mixed states of language is an extremely complex one, and will therefore be treated here at some length. As will appear in chapter 4, the combined knowledge of Middle English dialectology and of possible scribal behaviours has a relevance for textual criticism which has up to now been insufficiently recognised.
3.1.2 Mixtures in Middle English texts
In traditional research on modern dialects, it has been usual to select informants for the ‘purity’ of their dialect speech; conversely, in more recent sociolinguistic investigations, various kinds of mixture are studied for their own sake. For Middle English, on the other hand, the only available evidence is written; there are no cues that correspond to those of the spoken language, and it is therefore far more difficult to recognise what kind of mixture is in question. There is thus need for both theory and methodology to enable us to distinguish the following:
(ii) Variation of textual or codicological origin, e.g. layers of variants resulting from successive copyings.
(iii) Sociolinguistic variation, especially in writers affected by the spread of Standard English.
(iv) The combination of two separate dialects in a writer of mixed upbringing.
(v) Especially in the fifteenth century, an unusually wide range or eclectic combination of spellings in a single writer.
Of the above five categories, (ii), textually-conditioned mixture, requires the most extensive examination (3.2–5), and the general term used for this category will be Mischsprache. After a discussion of concepts and terminology (3.2), attention will be drawn to certain complex kinds of copying behaviour (3.3–4): some, which might at first sight appear to involve more mixture than they in fact do, will be called ‘pseudoMischsprachen’ (3.3), and another kind, ‘constrained selection’, will be discussed in 3.4. The prior definition of all these phenomena allows us to proceed to a more accurate description of Mischsprachen proper (3.5). The other categories of mixture, listed above as (iii), (iv) and (v), are discussed in 3.6.
3.1.3 Three types of copying
It is necessary at the outset to state the various treatments that are open to a copyist whose exemplar is in a dialect different from his own. Such a scribe may do one of three things:
B. He may convert it into his own kind of language, making innumerable modifications to the orthography, the morphology, and the vocabulary. This happens commonly.
C. He may do something somewhere between A and B. This also happens commonly. (McIntosh 1973, p. 60).
Categories A and B obviously admit degrees of consistency, and both shade into category C. The categories represent types rather than absolute distinctions, and the characterisation is in detail clinal. Nevertheless, the practices of most Middle English scribes may usefully be described in these terms. The degree of inconsistency admitted by categories A and B is clearly much smaller than what may be contained in C: by definition, C is anything that is not sensibly described as either A or B. The language of most scribal texts, or at least of substantial stretches of them, is readily identifiable as one or other of A, B and C, and it is relatively seldom that shading from one category to another presents operational difficulties for the analysis of any particular text. We should add, however, that a single scribe need not be bound to any one of these treatments over the whole course of a single text or collection of texts: although at any given point of text his treatment is describable as one and only one of these three types, a copyist may shift from one type of treatment to another, and ‘translational drift’ from type C to type B is in fact very common (3.3.2–4 below).
3.2 Some preliminaries: relicts and repertoires
3.2.1 Definition of ‘relict’
The term relict has various related but distinct meanings, e.g. in dialectology it means an earlier form not yet ousted by the spread of new forms from surrounding areas (4.4.1), and in sociolinguistics an original (childhood) form not suppressed by a speaker who has changed to a different type of speech (3.6.5). In the present chapter it will be used in its textual sense, to mean a form not part of a scribe’s own dialect, but an exotic that is perpetuated from an exemplar whose dialect differs from that of the copyist. Thus a scribe whose own dialect excludes mekell for ‘much’ may yet write mekell in the course of copying a text which includes it. Relict forms comprise a smaller or larger proportion of a copyist’s text according as he translates from the dialect of his exemplar more or less thoroughly. In normal use, ‘relict’ implies the co-occurrence of two separate dialectal elements in the same scribal output, and the literatim-copyist of a dialectally homogeneous text thus presents a trivial case of relict usage; usually, of course, it is inherently unrecognisable as such. A scribe who translated very consistently might yet reproduce an alien form from his exemplar by mistake. Such a relict would be a very isolated occurrence, and might be described as a ‘show-through’, the language of the exemplar here showing through the language imposed by the copyist.
Relict forms are defined usually by comparison of different literary texts copied by the same scribe. Forms common to all texts are assumed to belong to the scribal dialect; a form confined to a single text, and having one or more different functional equivalents in the other texts, is assumed to be relict. The definition obviously depends on the various texts being copied from diverse exemplars in different dialects. Such analysis is traditional, and not contentious, but it will appear that the text-restricted occurrence of variant forms is not always to be explained as relict (see ‘constrained selection’, 3.4 below). Moreover, it will appear that relicts may also be defined merely on the basis of their distribution through a single text (see 3.3 below, especially 3.3.2).
The difference between a text in which there is a large proportion of relicts, and one in which the language is characterised as a thorough-going Mischsprache, is obviously one of degree rather than of kind.
3.2.2 Active and passive repertoires
The terms ‘active repertoire’ and ‘passive repertoire’ may be defined thus. For written language, the active repertoire of any scribe is that range of forms he uses in writing that does not involve copying––in other words, it comprises his spontaneous usage. For most scribes, the active repertoire is not directly known, but deduced: since most scribes are known only from their copies of other writers’ texts, it is in principle possible that any of their forms is written not spontaneously, but copied. The passive repertoire comprises those forms which are not part of the active repertoire, but which are nevertheless familiar in everyday usage as the forms of other writers, and which the scribe does not balk at reproducing. This, obviously, is even more a matter for deduction and hypothesis than is the active repertoire, but it is a very useful category for the explanation of scribal behaviour. The following example will serve to illustrate the general principle.
Suppose that a scribe belongs to an area in which for ‘man’ the forms mon and man are both current. His own form is man, and spontaneously he never writes mon; but mon is thoroughly familiar as the form used in some adjacent communities, and by some individuals in his own. This familiarity is reinforced by the correspondence of the written variants to different and locally current spoken forms, viz. to [mɔn] and [man] respectively. Working from an exemplar locally produced, of which the dialect differs from his own in but few characteristics, the scribe is obviously under little pressure to translate in any self-conscious way. All that he meets is familiar, and most of it is what he would have written spontaneously. He reproduces the familiar forms of such an exemplar, including mon, and accordingly the language of his text differs only a little from what he writes habitually. In so far as it does differ, it represents his passive as opposed to his active repertoire, tolerated against spontaneous usage. Whether mon is recognised by the scholar as belonging to this scribe’s passive repertoire will depend on the linguistic variety of the other texts––if, indeed, there are any––extant in this scribe’s hand, and on the known dialect distributions for the relevant area. A form that on grounds of textual confinement might be accounted as a relict, may yet be more sensibly accounted as part of the passive repertoire if it can be shown that the form is well attested in the adjacent local dialects.
3.3 PseudoMischsprachen
3.3.1 Composite textsIt is the distribution of forms through a text that is crucial to the interpretation of its linguistic structure. To take first the extreme case of the composite text, suppose that a long literary text is written in successive stints by two different scribes, and that each scribe imposes consistently his own distinctive language on those sections of the text for which he is responsible. L1 and L2 are the respective scribal dialects, and they have few forms in common; it is immediately obvious that L1 and L2 are the work of two separate scribes because their scripts, S1 and S2 respectively, are very different. The linguistic and palaeographical structures of the text may be represented as in Figure 5 below.

A linguistic profile constructed for L1 is quite different from that constructed for L2, and taken individually, L1 and L2 are internally consistent. Since their scripts are not the same, there is no reason for a scholar to be misled into conflating L1 and L2 on a single profile.
Suppose now that a third scribe makes a copy of this text from the L1–L2 version, and that this third scribe is linguistically a literatim-copyist. He reproduces L1 and L2 exactly as they stand but, in doing so, associates L1 and L2 with a single script, his own S3. Seeing this S3 version, correctly, as the work of a single scribe, and knowing nothing of how it came into being, a modern scholar analyses it, and constructs a single unordered profile for the whole text; it does not matter here whether the profile is of the type described in 2.2 above, or is the traditional neogrammarian inventory. The scholar’s attention will be drawn to the multiple variants for nearly every item or category on the profile, and to the regional incompatibility of some forms (forms from L1) with other forms (forms from L2), all of which are represented as part of the same linguistic assemblage. No matter what the scholar does with the data, until and unless the distribution of forms through the text is considered––which will of course require re-analysis and the construction of an ordered profile––the language of the text will be written off as a Mischsprache.
Now it may be urged that in respect of the text the language is indeed a Mischsprache, and that the error lies in supposing that the text as a literary entity is of itself any fit category for linguistic description. In the latter observation there is indeed good sense, but there is an important distinction to be made. A text in which L1 forms and L2 forms were so intermixed that no single stretch of it could be described as either L1 or L2, but only as a conglomerate of L1 + L2, would be very different from that represented in Figure 5 above. We shall later consider the case in some detail, but it will suffice here to say that since the linguistic character of the extant copies may bear heavily on the extent to which the textual history can be recovered, for textual reasons alone there is everything to be gained by distinguishing the two types.
For linguistic as opposed to textual interpretation, the value of an ordered or sequential profile is here self-evident. The distributions of the two sets of forms, L1 and L2 respectively, do not overlap, except in so far as there are forms common to L1 and L2; and as we have defined them, their shared forms are few. The replacement of one set of functional equivalents by another, item by item, is textually abrupt, and an alert scholar will realise as much merely in the course of preliminary analysis. It is not the variants for just one item, or even for a few items, that suddenly change, but almost all variants for almost all items. Working from the profile, the precise point of each shift from L1 or L2 will be fixed by the commonly-occurring items; the textual gaps between poorly-attested items may be so large as to leave some shifts unrecorded, and taken by themselves these items may give the impression only of forms in free variation.
With only a partially ordered profile, it would be more difficult to discover the linguistic structure of the text, for the interval at which the scholar changes the colour of his ink, and the (here irregular) intervals at which L2 takes over from L1, are not likely to correspond. The linguistic diversity of the text, and the fact that the two sets of forms are discrete, should nevertheless emerge. Different inks should reflect markedly different proportions of L1 forms to L2 forms, and if the interval chosen is small, at least some inks may record one set of forms to the exclusion of the other. It should at least be clear that the language is not consistent from one stretch of text to the next, and that more detailed analysis is needed.
The existence of linguistically composite texts has long been known, at least since Breier’s study, published in 1910, of the Cotton manuscript of The Owl and the Nightingale. (Breier 1910; Atkins 1922.) This manuscript is the work of a letter-by-letter copyist, whose text reproduces at least some of the linguistic habits of the two scribes of an exemplar; the fidelity of this reproduction is such that the sections for which each of them was responsible can be determined precisely, even though it appears that the Cotton scribe superimposed some of his own habits indifferently on the text of both scribes. We have no reason to believe that the achievement of this scribe is unique. Indeed, considering that long texts were not uncommonly reproduced on the pecia system, with a separate scribe responsible for each gathering, it is at least likely that linguistically composite exemplars lie at only one remove from many of the extant manuscripts of long texts, manuscripts which are themselves the work of but a single hand. (Cf. Lewis 1981, pp. 256–60.) It is probably, however, only in part a reflection on the methods of analysis employed by most modern editors that the number of linguistically composite texts so far recognised is rather small. There are reasons for believing that literatim-copying or an approximation to it, which is the necessary condition for such composite texts to emerge, is less common in the later Middle English period than in the earlier; and the bulk of the Middle English output belongs to the later period. (See further in Appendix I.) An approximation to composite text may, however, arise from ‘constrained selection’ (see 3.4 below), which phenomenon is in later Middle English probably much commoner than literatim-copying: such tendency towards composite text emerges not uncommonly in the course of analysis. (Cf. McIntosh 1975, pp. 229–30.)
3.3.2 Progressively translated texts
The structure of the linguistically composite text is welldefined, the existence of the type is not contentious and, whatever the mode of analysis, it will be admitted generally that recognition of such cases depends on the textual distribution of functionally equivalent variants. In contrast, the second type of text we shall consider has scarcely been recognised at all, although it is much commoner than the first. The distributions of variants are less sharply defined, and such texts are in general likely to be dismissed as Mischsprachen. They are in fact not Mischsprachen at all, though by definition they always contain a stretch of text in which the language is a Mischsprache. The type may be called ‘progressively translated text’, and it seems to arise in the following way.
A copyist whose habit is to translate text into his own dialect takes time to get used to the language of his exemplar. The phenomenon of ‘working-in’ when reading unfamiliar hands is probably well-known to any scholar who has transcribed text from old manuscripts; and when out of practice, or faced with a particularly idiosyncratic hand, he may be acutely aware of it. The mediaeval scribe in these circumstances begins by copying fairly closely, even literatim, until he reads his exemplar fluently and at a glance. For the first few folios or so, he produces a text of which the language is not his own, but that of his exemplar. As he gets used to his copy-text, so he converts with increasing fluency the language of the subsequent text into his own. It may well be that in many such cases what happens is that the scribe moves from copying in a purely visual way to copying via ‘the mind’s ear’. Instead of reproducing a perhaps laboriously interpreted visual image, the visual image is now interpreted at a glance; and what is held in the mind between looking at the exemplar and writing down the next bit of text is not the visual symbols, but the spoken words that correspond to them. What the scribe reproduces is then the words that he hears, not the visual images from which they arose: regardless of whether his lips move, he is writing to his own dictation. The words as he hears them are then committed to vellum in his own familiar spellings, not those of some other scribe; only if he makes a special effort will his spellings correspond to those of the original. (For some further account, see Appendix I below.) A copyist attempting to conform to a written standard that was not his first-learned written language but a more prestigious alternative, might well make such an effort, but at least until the later fifteenth century it is doubtful whether outside the Central Midlands there was much dialectal pressure exerted by purely literary standards.
It is necessary to distinguish here between literary and documentary usages. Accommodations to Chancery Standard can be shown in northern English documents from at least the 1440s, and the letters of magnates, particularly those having regular correspondence with the Court, are similarly affected. In northern literary manuscripts, however, it is remarkable how little trace there is of accommodation either to Central Midland Standard or to Chancery Standard. The proper sphere of Chancery Standard was legal and administrative writing, in which its prestige was unquestionable because it was the language of what to all intents and purposes was the court of final appeal; its linguistic status was merely a reflection of the institutional status of the Chancery. We do not yet know whether individual northern writers switched from local dialect to Chancery Standard according to the text in hand, or whether the two linguistic outputs are the work of different scribal groups.
3.3.3 Progressive translation: an example
The above account of scribal behaviour is put forward as an explanation for texts displaying characteristics of the following sort. Let such a text be represented by Figure 6 below, and let the various kinds of language it contains be called (respectively) L1, L2 and L3. The whole text is in a single hand.

By the criterion of internal consistency (see further, 3.1.1, 3.5.1), L1 is a more or less homogeneous scribal dialect. For each item, the range of functional equivalents is small, and there are no forms geographically incompatible with each other. Similarly, L3 is internally consistent, but it is not the same as L1. L1 and L3 differ from each other in just the same way as do the separate scribal contributions to a linguistically composite text. A progressive translation differs from a composite text in that the transition from one type of language to the next is not abrupt, but progressive: L2 represents the transition from L1 to L3, and the shift is not absolute, but clinal. (The representation in Figure 6 hence uses stipple.)
L2 is recognised by strictly formal criteria. It contains for each commonly attested item a large number of functionally equivalent variants, and their geographical origins are diverse. At the start of the L2 text, L1 forms outnumber L3 forms, as L1 shades into L2; towards the end of the L2 text, L3 forms outnumber L1 forms, as L2 shades into L3. Within L2, the two sets of forms have no clear-cut textual distributions; L2 is a linguistic conglomerate, in which L1 and L3 forms are in more or less random variation. L2 is a thorough-going Mischsprache.
An unordered analysis of the language of the whole text would of course conduce to the view that its language is just another Mischsprache, and the co-occurrence of the L1 and L3 variants in seemingly random fashion might be cited from L2 in support. We have seen, however, that the textual spread over which L1 and L3 variants do co-occur is in fact very limited; although the limits of the L2 text do not admit precise definition, the language of most of the text is not a Mischsprache at all, but the internally consistent scribal dialect of L3.
L1 is relict usage, distributionally defined (cf. 3.2.1 above). It is relict just in so far as it is abandoned by the scribe in the course of copying this particular text: the distribution does not of itself establish to which scribe the relict language here belongs. In principle, it is quite possible for a scribe to begin by imposing his own language on the text, but as the text proceeds to abandon his own usage in favour of the increasingly familiar forms of his exemplar. In general, however, this kind of shift is probably much less common than the displacement of the language of an exemplar by the scribe’s own forms. These matters are considered further in Appendix I, but it may be noted here that a scribe who is (i) capable of copying exactly, and (ii) has the motive to do so, is likely to reproduce the language of his exemplar from the outset, rather than drift into literatim-copying after a bout of translation at the start. With cursive writing particularly, the latter history is not very plausible: see especially Appendix I, 1.6.
3.3.4 The textual status of progressive translations
It should not be thought that the definitions of L1, L2, and L3 are in any way dependent on our view as to how such texts as these come about. The criteria are formal and statistical.
The problem can be considered in the following way. L1 and L3 are samples, and we want to know whether they are samples drawn from the same one stock of variants, or whether they are drawn each from a separate stock. Suppose that there were some single stock, which consisted of all the things seen in L1 plus all the things seen in L3. If, from such a stock, we took two samples, one the size of L1, the other the size of L3, what are the chances that these two samples would be as different as L1 and L3 in fact are? Are the differences between L1 and L3 such as we would expect to appear quite commonly in a series of random distributions of the stock of variants between samples of these sizes, or are they very unlikely to arise in this way? If they are unlikely so to arise, then they may be taken as evidence that L1 and L3 are not samples drawn at random from a common stock, but are separate samples of two distinct stocks. In other words, this would be evidence that L1 and L3 are not to be lumped together and described as a single entity, but treated as two separate entities. That need not force the conclusion that they represent the usage of two different places, although in many cases that will be the most reasonable explanation. For immediate purposes, the important conclusion would be that L1 and L3 do not constitute a Mischsprache. (An appropriate statistical technique for assessing such distributions is the chi-square (χ2) test.)
We have already noted that progressively translated texts are common––though to avoid begging the question, it might be better to say that texts displaying the linguistic structure depicted in Figure 6 above are common. There is also a type that proceeds from an initial Mischsprache (the L2 stage), without a preceding stretch of more or less homogeneous usage (the L1 stage); this is very common, and it is our impression that texts of this type form a majority of Middle English translated texts overall.
The section characterised in Figure 6 as L3 is typically the bulk of such texts as are at all lengthy. It cannot, in the very nature of things, be proven as a general principle that the L3 stage represents the scribe’s own usage, the scribal dialect. Although there are reasons for thinking that in most scribal texts it does indeed represent the scribal dialect, and especially so when the script is cursive (see Appendix I below), there is no general guarantee that L3 does not represent a literatim-copy of the exemplar. For most linguistic purposes, however, individual responsibility for the state of language represented by L3 does not matter, although for textual analysis and codicological studies, and the association of a particular written language with a particular script, it is obviously important to know to which scribe L3 belongs. Whatever the direction of linguistic change in any particular case, however, a general conclusion of practical value for merely linguistic purposes may be stated. When samples of homogeneous usage are required, they should be sought well into the text copied by any given scribe. In general, usage is likely to be inconsistent in the early stages of a copy, just as the first part of a taperecorded interview between a modern dialect speaker and a field worker for a dialect survey is likely to be waste material. Both represent the accommodation of one type of language to another, and while the process of accommodation may itself be of great interest, it does not yield homogeneous samples of either usage. The scholar may of course be unfortunate in the place that he takes his sample, even late in the text, for scribes sometimes rest, and may do so for a long interval. The point at which the text is then resumed may then show some of the dialectal characteristics of the start: it may take time for a scribe to ‘work in’ to his task again. Barring cases such as this, the principle of sampling well into the text is sound.
3.3.5 Rhyming usage
A third type of pseudoMischsprache occurs very commonly in verse texts. It has long been recognised that a copyist who does not otherwise adhere to the forms of his exemplar may yet reproduce the spellings of rhyme-forms just as he finds them, so that even a copy at very many removes from the original may nevertheless preserve the authorial rhyme-spellings. Attempts to translate rhyme-forms from one Middle English dialect to another often result in spoiled rhymes: the Cotton manuscript of The Owl and the Nightingale contains some particularly well-known examples. Thus the south-west Midland forms heonne ‘hence’ and kunne ‘kin’ at lines 1673–74 reduce to mere consonance what was probably a full authorial rhyme of south-eastern ME kenne on henne. (Cf. Wrenn 1932, pp. 150–1; Stanley 1960, pp. 155–6; Dobson 1961, p. 374.) Some rhyme-translations may of course work, and self-rhymes can always be translated without loss, but in general the rhyming usage of later Middle English texts can be expected to differ sharply from the line-internal usage. The resulting Mischsprache is easily recognised for what it is and, in constructing a profile of a given scribal dialect, the rhyming usage must either be recorded separately, or ignored.
3.3.6 Alliterative usage
Alliterative constraint has been less well recognised, but it is readily demonstrated. The principle here is that, in order to preserve the alliterative fabric of the verse, a translating scribe reproduces the authorial forms whenever they occur in alliterative position. Thus, for example, in Bodleian Library, Douce 104, a Hiberno-English copy of the Piers Plowman C-text, initial g in ‘give’ and ‘gift’ is written only when these words are in alliterative position; elsewhere, initial ȝ is the regular spelling. Similarly, in alliteration, ‘church’ is here spelled always with k..k, but otherwise church is the regular form.
We should note additionally that the whole of the alliterative spelling, not just the alliterative consonant, is in principle to be excluded from the scribal dialect. We need not expect a scribe to reproduce merely that part of his exemplar’s spelling which preserves the alliteration, and convert the rest of the word into his own; he is at least as likely to take over the alliterative spelling lock and stock. Thus the Douce scribe writes kyrk(-), with variants kirke and kerke, not the hybrids kyrch(-), kirche and kerche. This is a matter of some importance, for supposing that ‘church’ did not occur in this scribe’s text other than alliteratively, we should have to conclude that we could know nothing about the scribe’s own form of the word, not merely that the first consonant was unknowable. For if working from his alliterative usage, we allowed that the initial consonant of his own form could not be determined, but nevertheless predicted that his medial vowel in ‘church’ was y or i or e, we should be plain wrong; and given that in the Mediaeval Hiberno-English dialects overall, chirch(-) and chyrch(-) heavily outnumber church(-), the Douce scribe’s avoidance of compromise forms with medial i of y is even more decisive than at first appears. Far from presenting an unusual case, however, the Douce scribe’s habits are thoroughly commonplace, and any number of other examples could be cited. Mutatis mutandis, similar considerations apply equally to rhyming usage.
3.3.7 ‘Scribal diglossia’
It is important to recognise how far such separation of scribal and authorial usages according to the demands of verse structure pervades the Middle English verse corpus. It is not unreasonable to speak here of a scribal diglossia; alternative forms like kirk and church, gif and yeue, les and las, may be consistently assigned over thousands of lines of a text in which they occur very commonly indeed. In alliterative verse like that of Piers Plowman, the scribal and authorial usages alternate constantly, and the cues as to which is appropriate in any given context are not nearly so blatant as are those for rhyme. In rhyming texts themselves, scribes on occasion scrutinise rather carefully that class of words marked by the line-end, translating where possible but otherwise maintaining the authorial rhyme. Non-northern copyists of the Prick of Conscience, for example, very commonly render authorial rhymes of OE ā on OE ā by o-spellings; such translation may be half-hearted, or carried out with great thoroughness, depending on the individual scribe. This change reflects, of course, one of the great dialectal divides in Middle English; but sometimes accurate rhyme translation introduces forms of much more restricted currency, implying deliberate conversion into strictly local language, just as far as rhyme permitted. Thus in Chetham’s Library MS 8008, a Mediaeval Hiberno-English copy of this same text, the original rhyme on ā in ‘there’ : ‘were’ ind. pl. is replaced by þore : wore, and other rhymes of ‘there’ on OE ā-words are regularly converted into ǭ-rhymes. This cannot, however be the work of the Chetham scribe, because þore and wore are not the in-line usage, and neither form is known in Mediaeval Hiberno-English. The Chetham scribe’s own language is notably consistent, but he himself seems not to have altered the rhyming language, regardless of whether his own dialect could have maintained the rhyme; þore : wore could have been altered to þere : were without loss. Rather, þore and wore here reflect the careful attention of a scribe from some English area where the two forms co-occurred. Evidently this scribe belonged to an area where ON váru replaced OE wœ̅ron/wēron, but where OE (and ON) ā became ǭ; a study of the non-authorial rhymes ought to enable a fairly narrow delineation of his local origins.
Note. The linguistic state of the text in the Chetham manuscript thus allows the definition of at least two non-authorial stages in its transmission: on the evidence of just this one manuscript, it would be reasonable to suppose that the Prick of Conscience was known in at least three different areas. See further, 3.5.4–5 and 4.2.1–2 below.
There are of course many copies of texts in which scribes fail to preserve the appropriate separations of authorial and scribal usages. They intrude their own forms to the ruin of rhyme or alliteration, and they are seduced by example into adopting exotic forms beyond the demands of verse. Even so, in a great many copies where the separation is far from absolute, numerical correlations exclude the likelihood that the choice of forms is merely random. The remarkable thing here is not that the copyists should fail to separate authorial and scribal dialects, but rather that so many copyists should attain such a high degree of consistency.
3.4 Constrained selection
3.4.1 Definition
Usage of a previously unrecognised type arises when a scribe follows his exemplar in such a way as to suppress altogether some of his habitual forms, and to alter substantially the relative frequencies of forms that are functionally equivalent. Except for the occasional relict, forms alien to the scribal dialect are not reproduced. This we call ‘constrained selection’, and ‘constrained usage’ is the language of the ensuing text. Constrained selection is perhaps best explained by example. In Table 1 below, suppose that the forms under C represent the whole repertoire of a scribe C in respect of the items listed; and let the forms X represent the equivalent range of forms found in an exemplar. It does not for the moment matter whether X is a homogeneous dialect or a Mischsprache.
| ITEM | C | X |
| it | it, itt | itt |
| they | þai, þei, þay | þai, þay |
| much | moch | mykel |
| which | wych ((wilk)) | wych, wilk | each | iche, ech | iche, ilke, ylk-a |
of relative frequency: wilk is in C-dialect a minor variant.
C does not reproduce any form that is alien to his own dialect, but when he encounters a familiar form he reproduces it as it stands in the exemplar. To that extent he does not translate freely or as a matter of course. Presented with X-usage, C’s copy has the following characteristics. For ‘it’, only itt is written: C never finds his variant form it, but only the equally acceptable itt, and itt is hence the sole form of his copy. Similarly, þei is excluded: C’s other forms, þai and þay, are reproduced as encountered. For ‘much’, C always substitutes moch for the alien mykel of the exemplar. In the same way, C’s iche replaces X’s ilke and ylk-a, but corresponds to iche wherever X writes it; ech, like it and þei, is excluded altogether. ‘Which’ introduces relative frequencies: spontaneously, C writes wilk only as a minor variant, and his preferred form is wych. In X, however, wych and wilk are of equal status, and C’s wych ((wilk)) gives way to wych/wilk in his copy. The usage of this copy we may call ‘X-constrained C-usage’, and it is represented in Table 2 below. Beside it appears ‘Y-constrained C-usage’. This is the language of another text copied by C, from an exemplar written by a scribe Y; Y’s own forms are listed alongside.
| ITEM | X-constrained C | Y-constrained C | Y |
| it | itt | it | it, hit |
| they | þai, þay | þei | þei, hi |
| much | moch | moch | moch |
| which | wych, wilk | wych | wych |
| each | iche | ech ((iche)) | ech ((iche)) |
It will be seen at once that X-constrained C and Yconstrained C are so unlike that, even on these few points of comparison, by linguistic criteria alone they would probably never be identified as the outputs of a single scribe. Whereas such failure of identification is not in the least surprising for a literatim-copyist, who reproduces the language of some other scribe whenever he copies a text, the remarkable thing here is that the scribe C has not introduced a single exotic form into his copied texts. All that has happened is that different subsets from a single repertoire have arisen in such a way as to make the total repertoire unpredictable from any single subset, except in so far as the presence of a form in any subset guarantees its presence in some status or other in the total repertoire.
3.4.2 Constrained selection and dialect differences
From this there follow certain general observations on the character of dialectal differences overall. Dialects may contrast in one or two fundamentally different ways.
(2) The repertoire of forms is the same in D1 as in D2, but the relative frequencies of functional equivalents differ: thus a form that is in dominant frequency in D1 appears only as a minor variant in D2, and the dominant equivalent in D2 is a minor variant in D1.
In principle, therefore, two scribal dialects may be assignable to different places without either containing a form that is not also in the other. In most dialectal continua, however, dialects differ from one another by a combination of both types of difference, and the limiting cases presented by types (1) and (2) are probably never realised.
Constrained selection depends obviously upon a substantial overlap between the dialect of the copyist and that of his exemplar; differences of type (1) exclude it absolutely. Constrained selection has to do (a) with the differing relative frequencies of shared forms, as in type (2), and (b) with the suppression of those forms in the copyist’s dialect that are not shared with that of the exemplar, in favour of forms which are common to both. The larger the common core of shared forms and usages, the more likely it is that the textual language of a copyist will be constrained by that of his exemplar. It is hence most likely to arise when a copyist obtains his exemplars from divers local sources: exemplars written in dialects radically different from that of a scribe who is not a literatim-copyist, can be expected to yield either translations or Mischsprachen as the language of his copies.
3.4.3 Types of interference
To conclude this part of the description, it will be useful to set out more fully the types of interference that can arise between exemplar and copy. The notation is abstract: a comprehensive account is not well-handled by narrative description. Table 3 below illustrates the constraints exercised by various hypothetical exemplars on a hypothetical copyist called ‘S’, the constraints differing according as S shares forms and relative frequencies with the various exemplars.
| S-ACTIVE REPERTOIRE | S-COPY | ||
| ITEM | (Spontaneous usage) | EXEMPLAR | (constrained usage) |
| A (forms a1 - a3) | a1 a2 a3 | a1 | a1 |
| a2 | a2 | ||
| a3 | a3 | ||
| a1 a2 | a1 a2 | ||
| a1 a3 | a1 a3 | ||
| a2 a3 | a2 a3 | ||
| a1 a2 a3 | a1 a2 a3 | ||
| B (forms b1, b3) | b1 ((b2)) | b3 ((b1)) | b3 ((b1)) perhaps tending to b3 b1 |
| C (forms c1, c2) | c1 | c2 | c1 perhaps tending to relict c2 |
| D (forms d1, d3) | d2 | d2 d3 | d2 perhaps tending to relict d3 |
For item A, exemplars in which the relative frequencies of a1-a3 diverge,
have not been entered; but the effects of such divergences on an S-copy
are readily extrapolated from item B.
It is important to make the distinction between genuinely relict forms and constrained usage. A relict form is one that does not belong to the scribe’s own dialect at all, but is reproduced as an exotic from the dialect of an exemplar (see 3.2 above). ‘Constrained usage’ is the accommodation of a scribe’s own repertoire to that of his exemplar, which accommodation does not extend to the reproduction of exotic forms. Constrained usage may exclude forms expected in the dialect of the copyist; and the relative frequencies obtaining between variants in the scribe’s spontaneous usage may be much altered by adherence to the usage of an exemplar.
Constrained selection operates within the limits of the active and passive repertoires. What lies outside them is exotic, and the incorporation of the exotics involves either textual relicts or a Mischsprache. It follows that for a detailed assessment of any scribal text, attention must be given to the character of the adjacent dialects. This is in the first instance a consideration of the attested co-occurrences of forms in linguistically congruent outputs: absolute geographical origins are of merely incidental importance here, although linguistic and geographical continuities are in fact closely related. By assigning a scribal dialect to, say, the general area of south Lincolnshire, we have as a matter of course specified the relevant subset of Middle English dialects with which the dialect in question is to be compared. We shall consider in a later section the use of dialect matrices that are in principle linguistic rather than geographical constructs (see 3.5.4–5 below).
In fifteenth-century English scribal dialects, a considerable degree of internal variation has to be reckoned with, and a characterisation of such dialects by lexical rather than phonological categories contributes to a general impression of inconsistency. Within a single scribal dialect, for any given item, two or more forms may occur as functional equivalents, whether in similar or differing relative frequencies. A check on the range of likely variants in the dialect of a scribe whose only surviving output represents constrained rather than spontaneous usage, is provided by inspection of the ranges of forms admitted by those scribal dialects that are geographically adjacent to it. Accordingly, when in the same scribal text two or more forms that are functionally equivalent occur in significantly skewed distributions over the text as a whole, then even if one of these forms could be relict, it must in principle be admitted as a probable (minor) variant in the dialect of the scribe in question, if it is attested in one or more of the adjacent dialects.
3.5 Mischsprachen
3.5.1 The characteristics of Mischsprachen
A Mischsprache proper is for present purposes what the late Professor Tolkien aptly described as a ‘nonce-language’, ‘an ‘accidental%’ form’ of language, occurring in all its details only in one text (Tolkien 1929, p. 105). Its defining characteristic (cf. 3.1.1) is the persistent co-occurrence of dialect forms whose regional distributions are such that their geographical overlap cannot reasonably be supposed. For modern dialects, it is in principle possible to determine absolutely whether the regional distributions do indeed overlap; although even here, a dialect survey can in practice represent the usages of only a small sample of the total population, and the isogloss patterns remain inevitably somewhat speculative in detail. (Isoglosses are in fact interpretative, and it is notorious that no two cartographers will draw precisely the same isoglosses for the same set of data.)
A text containing the unique combination of, say, the forms f1 and f2 need not represent a Mischsprache: it may well provide good evidence, indeed the only evidence, for the geographical overlap of the distributions of f1 and f2. Such would be the conclusion if f1 and f2 were, on the other evidence, so distributed that an area lying between the domains of f1 and f2 had no functional equivalents of f1 and f2 attested within it, and if, on the evidence of all its other forms, the dialect of the text containing f1 and f2 were itself assignable to that area.
For the purposes of the preceding argument, it does not matter whether f1 and f2 are functionally equivalent, or represent variant forms of two separate items. It is worth noting, however, that in cases where f1 and f2 are functional equivalents, then their co-occurrence in some dialects is predictable when their geographical distributions are of the type here considered (cf. 2.3.5 Border-areas).
The sheer number of functionally equivalent variants does not therefore guarantee the existence of a Mischsprache. The co-occurrence of unlike variants whose geographical domains overlap is not, however, the only source of apparent heterogeneity. Multiple variants may arise from the extensive adoption of analogical spelling, which in principle affects the whole of the eligible lexis. Additionally, what may be called ‘derived variants’ extend the range of permissible spellings for a single word, the interchange of orthographically equivalent segments creating new forms by permutation. Thus, for example, the co-occurrence of þai and þey for ‘they’ may imply the additional forms þay and þei; whereas the form hi stands outside the group, in that it cannot be derived from any permutation of the existing segments.
In general, a relatively large number of forms that are functionally equivalent, and not accountable in any of the three ways outlined above, is the hallmark of the thorough-going Mischsprache. It tends to consist of the sum of the available forms rather than of a selected subset, and in this it contrasts strongly with other types of mixture, e.g. that which arises as spontaneous usage in accommodation to an autonomous written standard (cf. 3.6.3 below): the ‘purging of grosser provincialisms’ involves, self-evidently, selection and direction of change, not the mere conflation of the indigenous with the exotic. (Cf. Samuels 1963, p. 93; Davis 1952, esp. p. 219; 1954, esp. p. 130.) In Mischsprachen, however, the mere conflation of variants is exactly what we should expect. It is scarcely plausible that a contaminating scribe should reproduce the forms of the exemplar for (say) half the items in the textual inventory, excluding his own equivalents absolutely, but for the remaining items impose his familiar forms and suppress those of the exemplar. Rather, we should expect him to produce a text containing a more or less random sample from his own forms and from those of the exemplar.
3.5.2 Example of a typical Mischsprache
The principle may be illustrated by the following hypothetical example. In Table 4 below, the forms listed under C are the forms of a scribe C’s own dialect, and are the only forms that he produces spontaneously from the items in question. The forms listed under E are those of another, very different dialect, as they are encountered by C in his exemplar for a fairly lengthy text.
| ITEM | C | E | M | O |
| it | hit | it | hit, it | hit |
| them | ham | tham | ham, tham | tham |
| such | soch | swilk, silk | soch, swilk, silk | soch |
| which | whoch | whilk | whoch,whilk | whilk |
| much | mochil, much | mekel | mochil, much, mekel | mochil, much |
| are | beth | ar, arn | beth, ar, arn | ar, arn |
| after | aftir | efftir | aftir, efftir | aftir |
| 3 sg pres. | -ith, -yth | -ys, -is | -ith, -yth, -ys, -is | -ys, -is |
Suppose now that C copies the text of his exemplar, and that he treats the language inconsistently: sometimes he substitutes his own form for that of E, sometimes he reproduces E’s form just as it stands. The language of the ensuing copy then represents a conflation of C-usage and Eusage, so that the inventory of forms for this text is the sum of the C-forms and the E-forms, as represented under M in Table 4. For each of the items considered, the text admits at least two variants. Although for some items, there might be particular reasons favouring the exclusion of certain variants, overall we should expect an unusually large number of variants per item. These variants are not of the derived type (see 3.5.1 above), nor do they represent the co-occurrence of geographically adjacent forms (see 2.3.5 above). Certainly we should not expect the scribe to fix on, for example, his own forms for ‘it’ and ‘much’ (and thus never write it and mekel), but fix on the E-forms for ‘which’ and ‘are’ (and thus never write whoch and beth): a Mischsprache like that represented under O (Table 4 above), is inherently implausible. Only if the text were very short, and each item turned up only a few times, could an assemblage like O be expected to emerge; and such a sample would, of course, be a wholly inadequate basis for deductions about C’s linguistic habits as a copyist.
3.5.3 Extent and complexity of Mischsprachen
In principle, the Mischsprache affects as many items as are not realised by the same set of forms in each of the contributing dialects: a pair of dialects that differed in their forms for one and only one item could produce only a trivial case of a Mischsprache. Obviously, the extent to which a Mischsprache can develop depends on the degree of dissimilarity between the separate dialects contributing to it. Additionally, constrained selection, especially in so far as it affects relative frequencies of forms common to the different dialects, may contribute to the overall complexity of the Mischsprache.
In textual studies, it has been customary to assume that the number of past copyists who could have left traces of their characteristics in a single surviving Middle English manuscript is vast, limited only by the rate of copying that could have been physically possible between the time of composition and the date of the manuscript in question; in other words, that such manuscripts are ‘mosaics’ or ‘pastiches’ of forms surviving from an indeterminately large number of copyings, and are therefore of virtually unlimited linguistic complexity. In practice, it is clear that only a minority of surviving Middle English texts can be accounted Mischsprachen, and when this question is considered statistically, it turns out that complex mosaics are the exceptions, and that the majority of our Mischsprachen are likely to contain forms from much fewer copyings. For a discussion of the statistical probabilities see Appendix II. Cf. also Lewis and McIntosh 1982, pp. 23–25.
3.5.4 Dialectal analysis of Mischsprachen
The constituent dialects of a complex Mischsprache may on occasion be defined with some confidence in the course of attempting to localise it on the overall dialect map. (Cf. McIntosh 1962 on the alliterative Morte Arthure, though the theoretical importance of such methods was not there the object of inquiry.) In so far as the separate layers of a Mischsprache can ever be defined procedurally, mapping offers by far the most powerful technique. ‘Mapping’, as will appear, is here to be understood in an abstract rather than a geographical sense (see below, 3.5.5). The operation is in principle as follows.
Given the linguistic profile for the Mischsprache in question, it is attempted to place (or ‘fit’) the dialectal conflate so represented into the matrix that is the relevant collection of dialect maps. Just because the dialect is not regionally homogeneous, but contains different geographical subsets, it will not be localisable in any one place: wherever it is put, there will always be some forms that are recalcitrant, forms that interrupt the continuities of the distributions presented by the maps. Thus, for example, at a given location the Mischsprache’s forms for ‘they’, ‘much’, ‘after’ and ‘work’ might all square perfectly well with the forms for these items attested in the neighbouring profiles; but the forms for ‘each’, ‘which’ and ‘think’ might be wholly unlike any of the forms that are already mapped in this area. The first move is therefore to find that location which accounts for the greatest number of the Mischsprache’s forms. Inevitably, this location will not emerge without a certain amount of trial and error: just because there are separate geographical subsets in the overall mix, there are separate and competing potential locations. Nevertheless, the number of competing locations remains very limited; the limit is set, obviously, by the number of separate regional contributions to the Mischsprache, and as we have noted, this is unlikely to be large (see 3.5.3 and Appendix II). Once the optimum location is found, attention is directed to the residue of forms that cannot be squared with that location.
Taking the forms of the residue as composing, for present purposes, a separate profile, the attempt at placing is begun afresh. Again, the object is to find that location which accounts for the greatest number of forms; and again, once found, there may well be a substantial residue of recalcitrant forms. This residue is treated in exactly the same way as the first; it is a ‘dialect’ to be localised, and its optimum placing may yet leave further residue. The process is repeated until all forms are accounted for, until all the residual profiles emerging in course of the operation have been placed.
3.5.5 Interpretation of the analysis
It would be easy to conclude that the total number of profiles thus produced, including that for the original Mischsprache, represents the number of regionally distinct contributions to the Mischsprache with which we began; and that the placings of these profiles reflect the geographical origins of each scribe who contributed to it. In general this conclusion is probably sound, but it bears closer inspection.
Firstly, only as long as we assume that the number of geographical subsets is small rather than large does the conclusion hold. Nevertheless, there is good reason to believe that multiple contamination is not common: it takes only one scribe, who habitually translates from the dialect of an exemplar into his own, to break the chain of contamination, to convert the language of the text into a single and internally consistent dialect. Since such scribes seem to have been a majority in the later Middle English period, we should not expect to encounter very often extended chains of contaminating scribes, each of whose contributions was in some degree preserved in the final text. The odds against it are just too great (cf. Appendix II). Similarly, in epistemological principle, there is obviously good reason for postulating fewer rather than more separate contributions to the Mischsprache. The more contributions we postulate for which we do not have decisive evidence, the more likely it is that in our reconstruction we shall be mistaken; and since we wish to be mistaken as seldom as possible, the fewer opportunities that we give ourselves to make undetectable mistakes, the better. For both these reasons, therefore, the principle should be adopted of assigning as many of the Mischsprache’s forms as possible to a single geographical subset, even though such a layer could itself be split into further subsets each having independent local origins. Only where there is good extra-linguistic evidence for postulating geographical subsets beyond the necessity established by the requirements of mapping should such additional subsets be so postulated.
Secondly, the notion of placing needs some comment. The importance of placing is here not that we can say things like ‘this contribution belongs to Bedfordshire’, but that we can say ‘there are attested dialects with which this postulated dialect, this subset of the Mischsprache’s total inventory of forms, coheres’. The dialect profiles already mapped are the fixed points in the matrix that is the overall dialect continuum. They are fixed in the same sense that, of all possible combinations from the total inventory of Middle English forms, these are the select combinations that are attested as the sustained usage of some one place or scribe. They therefore define the probability of existence for all other combinations: a combination that can be fitted into the matrix without interrupting the continuities of distributions already established, is inherently more likely to have existed than one which cannot: it is an intermediate stage between two or more attested dialects of the continuum. The geographical placing is incidental: what matters here is that we can say a given combination is likely or not likely to have existed as the internally-consistent usage of any place.
If, therefore, to return to the Mischsprache, we can say that a maximal subset of its forms could have existed as the usage of some one place, then it is reasonable to postulate that it did so exist. In other words, we define the largest possible contribution for each scribe in the chain of copying and, in so doing, we postulate the smallest number of scribes compatible with the dialectal state of the text. Conversely, it is clearly not reasonable to postulate a given subset as a single contribution if in all probability it could not exist as the dialect of some one place. At the very least therefore, mapping excludes the definition of improbable subsets. Since we believe that the number of subsets postulated should be minimal, it is accordingly likely that the procedure of defining the several subsets minimally, as successively unlocalisable residues, does in fact recover the separate scribal contributions as they really are. There may well be overlap, of course: a form common to both of the areas defined to account for two residual subsets, could in principle have been introduced by a scribe from either area. The method defines in the first instance the largest possible contribution from each successive location established. Selfevidently, however, that does not determine to which scribal contribution a form that could be common to several of them does actually belong: it may indeed have been introduced in all of them. What can be defined is the distinctive contribution of each individual scribe thus postulated.
Note. It should perhaps be emphasised that the ‘mapping’ of the constituent subsets of a Mischsprache is a purely analytic technique. Mapping is a way of defining the separate scribal contributions, and incidentally it is a way of establishing probable geographical origins. It is not a way of wringing out more data to put on the maps, as if we had discovered some new ‘informants’: not only would such evidence be successively deficient for the number of items attested as each residue was abstracted, but the integrity of the orthographic detail could never be trusted––it is entirely possible for a scribe to lay an irregular veneer of his own spelling habits over forms that have no part in his own dialect. It is not enough to be confident that, say, some approximation to michell was present in a well-defined subset of the Mischsprache: before it could be entered on the map in the place from which that subset derives, we would need to know that the original spelling was not, say, mychyl, that some subsequent scribe’s preferred e against y, and word-final -ll instead of -l, had not been superimposed in the course of transmission; and the possibility that such a form was a compromise between forms of the much and mikell types might also have to be considered.
3.6 Other kinds of mixture
3.6.1 Their differences from Mischsprachen
The other kinds of mixture, briefly indicated in 3.1.2, do not, strictly speaking, qualify for the title of Mischsprache as defined in 3.5.1 above. The main differences are as follows.
(ii) Whereas Mischsprachen are ‘nonce-languages’ limited to a given single text, the other kinds are no more ‘nonce-languages’ than any idiolect is, when viewed sociolinguistically. It is only from the standpoint of the dialect investigator that they are to be regarded as mixtures. Unlike Mischsprachen, they can be found in continued use in a series of texts and, in varying degrees according to kind, they are as consistent and predictable as texts written in ‘pure’ dialect.
Since we are here dealing with a broad spectrum of idiosyncratic forms of the written language, it is probably inadvisable to attempt a typology of them; but the following sections will give some idea of the varying degrees of consistency that they show.
3.6.2 Writers of mixed upbringing
There are a number of cases in Middle English of writers who combine, in a consistent system, forms that we would normally associate with two different places. The example par excellence is the poet John Gower. When Gower’s language (as represented in the two ‘best’ manuscripts) is analysed, it shows two layers, which at first sight one might think were both scribal, or perhaps scribal plus authorial. There are, however, two big differences from the normal two-layer Mischsprache: firstly, some typical forms from each layer are required by the metre, and secondly, the spelling is consistent and predictable throughout. The latter fact, taken on its own, could be explained as due to a scribe who, as a result of his upbringing, had combined features of two separate regional spelling systems into a single system; but, since these two spelling systems tally exactly in their respective provenances with those of the features that are metrically required, the only possible explanation is that the combination represents the author’s own idiolect, written and spoken. It is confirmed by the fact that the two constituent sets in question localise precisely in two separate places in south-west Suffolk and north-west Kent with which the Gower family were associated (Samuels and Smith 1981).
3.6.3 Dialect and standard
Today, a speaker who combines dialect and standard is commonly regarded––in sociolinguistic terms––as doing no more than code-switching between formal and colloquial styles. There is therefore some doubt as to whether it is valid to regard such a combination as a ‘mixture’ for any period in the history of the language. However, the period 1420–1550 is the only one in which writers can be shown to have been replacing their own original regional spellings by the more prestigious ones of the emerging standard. The phenomenon must therefore find mention here since, at the very least, it constitutes a limitation on our evidence for dialect.
The process can be found in many writers, notably Edmond Paston (Davis 1952), Caxton (Samuels 1981), Cardinal Wolsey (Gómez Soliño 1981 and 1984). But such cases are of writers who happen to have left us enough evidence over a period for us to observe the change taking place. The number of individual and anonymous texts from the fifteenth century which show some kind of semi-standardisation is much greater still. Since the features replaced naturally include those that are most markedly dialectal, such texts are usually difficult to localise with any precision (Samuels 1981). The consistency of this language varies from text to text, and is never likely to be as high as that of the example in the preceding section; but at least the replacements are motivated, not random, and are made from a fairly limited and predictable subset of the language (cf. 3.5.1).
3.6.4 Extended and/or eclectic repertoires
Towards the end of our period, as a phenomenon distinct from the written standard, we find a growth of regionally mixed spelling systems. To explain this, we must assume that, because of the growth of centres of education (especially grammar-schools), regional spellings which had hitherto varied from parish to parish became less specific to given places, and appear in combination in the spelling systems of individual writers merely as a result of their education and upbringing and without dialectal significance. There is no evidence from these writers’ spellings that they are influenced by Standard English, and yet there are also no grounds for supposing that their regionally mixed spellings reflect any corresponding mixture in their speech. All one can say is that their active repertoires contain a greater range of spelling variants than had been usual before the mid-fifteenth century. Such extended repertoires still display a degree of consistency, but the seemingly accidental nature of the combinations gives them a superficial resemblance to Mischsprachen. (For examples, see Samuels 1981, pp. 46–8.)
3.6.5 Scribal eclecticism: an extreme case
If it is possible to judge from the single case so far discovered, the active repertoire of a professional scribe could, perhaps partly as a result of copying the same work repeatedly, become extended to a greater degree than in the cases mentioned above. The scribe in question either wrote or contributed to eight surviving copies of Gower’s Confessio Amantis, two copies of Chaucer’s Canterbury Tales, one of Piers Plowman and one of Trevisa’s translation of Bartholomaeus, De proprietatibus rerum (Doyle and Parkes 1978), and the language of these has recently been studied in some detail (Smith 1985). Dr. Smith has demonstrated that he was of south-west Midland (probably Worcestershire) origin, had migrated to London and adapted his regional spelling to metropolitan use. The basis of his active repertoire is thus a core of forms common to London and Worcestershire texts of ca. 1400; but it also includes a small proportion of south-west Midland forms which must be termed relicts in the sociolinguistic sense (i.e. they survive from his youth), as well as a small proportion of Kentish forms learnt from his copying of Gower. His passive repertoire evidently includes many other south-west Midland forms which he continues to use in copying from western exemplars.
In spite of the disparate origins of this scribe’s repertoire, there is an overall consistency in his total very large output, e.g. in the way he uses a thin scattering of south-west Midland forms when copying Gower, or a thin scattering of Gowerian forms when copying Chaucer, Langland and Trevisa. His choice of one variant rather than another can never be predicted for given contexts, but the overall proportions of the variants are broadly predictable. His work thus provides us with a striking and very complex example of an only apparent, not real, Mischsprache.
Chapter 4 APPLICATIONS
A linguistic atlas of a past stage of the language is more than its name implies: it is a research tool that can be applied in many different ways. The following account cannot claim to be comprehensive, but it attempts to indicate some of the spheres in which the Atlas can be shown to assist in extending our knowledge; further applications in these and in other new directions will no doubt occur to readers themselves (cf. also chapter 5 below). There are, naturally, many other branches of mediaeval studies which can be aided by dialectal information, such as social and legal history, and the history of science and medicine.
4.1 The localisation of literary texts
4.1.1 Scribes and scriptoria
It is no exaggeration to state that the Atlas is, in addition to being ‘linguistic’ in the narrower sense, a means towards providing the literary map of mediaeval England. But, in making such a claim, we need to be explicit about its basis: the Atlas tells us, in essence, where the scribe of a manuscript learned to write; the question of where he actually worked and produced the manuscript is a matter of extrapolation and assumption. We know very well that scribes travelled: an extreme case is that of John Wykes, an amanuensis of the Paston family in Norfolk, who writes in a slightly standardised but clearly identifiable Devon dialect; and there are many instances of manuscripts that were evidently produced in London but were written by immigrant scribes from the south-west Midlands, the north-west Midlands, or the north. In general, however, more trustworthy guidance on this question comes from regional manuscripts that were written by a number of collaborating scribes. These show that the scribes were either (a) local, or (b) had migrated from a surrounding catchment-area within a radius of, on average, some ten or fifteen miles.
Scribes were thus usually ‘local’, but only in a broad sense of the word. For example, the famous collection of lyrics in British Library, Harley 2253 was almost certainly produced at Ludlow (Revard 1979), but the language of its scribe suggests that he had learned to write some ten miles further south, in the Leominster area.
4.1.2 Two or more manuscripts by a single scribe
There are many cases of surviving manuscripts that were written by the same scribe, but they are almost invariably in different collections and repositories, and identification of them is often either fortuitous or made by palaeographers from their knowledge of purely graphetic details (cf. 3.6.5). A more direct method is by means of linguistic profiles: its advantage is that the recognition does not have to come from memory and experience, but simply from the process of localising the two profiles. When that has taken place, they are at once recognised as identical, even in cases where the scribe had changed from one kind of script to another (McIntosh 1974, p. 604; 1975, p. 221; Benskin 1977, p. 513).
Such identification by profile and localisation naturally contributes to our knowledge of scribal history and codicology; but it can also, in turn, increase and consolidate our knowledge of manuscript distributions. For example, early in the investigation, preliminary analysis suggested that Cambridge, Trinity College, 383 (R.3.8) (Cursor Mundi) was likely to have been written in the Lichfield area. But this localisation was capable of proof, for when the profile of this manuscript was compared with that of Oxford, Bodleian Library, Rawlinson A 389, a manuscript with Lichfield associations, it turned out that the identical scribe had written both the Trinity manuscript and part of the Bodleian manuscript (McIntosh 1963).
4.1.3 Scribes and authors
How much the localising of a scribe’s work will tell us about the provenance of the author is a question that yields varying results according to the circumstances of each case, but the information is always useful. In some cases, it is decidedly confirmatory: for example, it tells us that the works of the Gawain-poet were copied not far from where, on other grounds (lexis, rhymes, knowledge of local topography) we would expect him to have lived; conversely, it tells us that the three surviving manuscripts of Robert Mannyng’s Handlyng Synne were all written very far from Bourne. It will tell us which manuscripts were produced nearest to the known provenances of authors like Robert of Gloucester, Trevisa, Richard Rolle or Walter Hilton; on the other hand, if the author or his provenance is unknown, it will at least tell us the area or areas in which, on the evidence of the surviving manuscripts, his work was copied and read.
4.1.4 Multiple copies of the same work
It is here, in the dialectal distribution of multiple copies (especially of popular works), that we are likely to learn most. The map showing the distribution of the Prick of Conscience manuscripts yields the conclusion that ‘nearly four fifths of the counties in England can claim at least one copy of the poem, and some have more than one’ (Lewis and McIntosh 1982); that for Mirk’s Festial shows a predominantly north Midland distribution with only sporadic representation further south (Wakelin 1967); while that for the Scale of Perfection shows its largest spread in an east Midland area stretching from Nottinghamshire to Norfolk and Essex, with smaller representations in Yorkshire, the London area, Worcestershire and Dorset (McIntosh, unpublished). The map for Piers Plowman shows marked differences between the A, B and C-texts, with the B-texts mainly London or eastern (but often with western relicts), and the C-texts concentrated in the south-west Midlands (especially south Worcestershire, and south-east Herefordshire, i.e. the Malvern Hills area), while the peripheral distribution of the A-texts illustrates a phenomenon found elsewhere by palaeographers, that the earliest manuscripts of a work are found on the periphery of the culture (Samuels 1963, 1985; see further 4.2.2 and 4.2.4 below).
The above examples should suffice to show that, however varied the information in each case, it will always increase our knowledge of the regional patterns of literacy and literary culture, book production and circulation.
4.2 Textual history
4.2.1 The detection of layers in single texts
The method of detecting layers of copying in mixed texts was described in 3.5.4 above. As was pointed out there, one cannot always be sure of the exact limits of the layers since some forms might be common to more than one subset; but the diagnostic features for each subset are identifiable, and it was on that basis that it was possible to isolate the layers in Bodleian Library, Bodley 959 of the Early Version of the Wycliffite Bible (Samuels 1969). Greater accuracy is possible when a single scribe copied a number of works from disparate exemplars: one can then deduce that forms common to all the works are those of the ‘uppermost’ layer, whereas forms that occur in parts of the manuscript only belong to the previous layer or layers (3.2.1). In the case of the alliterative Morte Arthure (Lincoln Cathedral Chapter Library 91 (A.5.2)), it was, as it happened, possible to employ this procedure twice over, with the result that three separate layers could be detected (McIntosh 1962).
4.2.2 Layers and stemmata of major manuscript traditions
It is noticeable that editors of large groups and families of manuscripts rarely give weight to dialect variants. Their concern is exclusively with semantically distinctive or otherwise ‘substantive’ variation, whereas dialect variants––though sometimes recorded for their own sake in the apparatus ––are regarded as ‘non-substantive’ and merely incidental features of textual transmission. That this procedure misses important information can be shown from two manuscripts of the Piers Plowman B-version, Bodleian Library, Laud Misc. 581 (L) and Rawlinson Poet. 38 (R). Skeat noticed that where these two manuscripts agree, the agreement is close, ‘frequently extending even to peculiarities of spelling’ (1869, p. xi); but the Kane-Donaldson edition, on the grounds of major substantive variation, treats these two manuscripts as belonging to separate branches of the stemma, leaving any similarities to be explained––as is normal in problematic manuscript traditions––by subsequent contamination or convergent variation.
It is here that the distinction between substantive and non-substantive variation becomes crucial, for it is wholly inconceivable that a scribe (or ‘editor’, or ‘redactor’), when comparing two exemplars, could have been led to prefer forms simply on dialectal grounds. The solution to this seeming contradiction was provided by the profiles of L and R, which showed (a) that both manuscripts contained the same relict layer but widely differing uppermost layers, and (b) that certain random alternations of variants, like any and eny, ȝif and if occurred at exactly the same points in the running text in both manuscripts. From this only one conclusion could be drawn: since, on substantive grounds, both manuscripts are widely divergent, the random non-substantive variations could be due only to the archetype common to manuscripts L and R, and, in view of their position in the stemma, to the whole B-tradition; in other words, these two manuscripts could now be proved to contain archetypal spellings.
4.2.3 The recovery of archetypal spellings
The problem of recovering archetypal (and potentially authorial) spellings is one that varies greatly with the particular circumstances of each large manuscript tradition, and methods have to be adapted accordingly. As we have already seen (3.6.2), the Gower manuscript tradition provides a striking case in which dialectal knowledge can be applied to demonstrate that certain manuscripts must be regarded as virtually equivalent to author’s holograph. This same information can then be used to further our knowledge about Chaucer’s spelling. The key factor here is that the scribe of the Hengwrt and Ellesmere manuscripts of the Canterbury Tales also happens to be one of the scribes who shared in the copying of Gower’s Confessio Amantis in Cambridge, Trinity College R.3.2 (Doyle and Parkes 1978, p. 170). By comparing this scribe’s treatment of his two very different exemplars, it is possible to define which forms are his own and which are the Chaucerian and Gowerian relicts. This evidence, corroborated by that of rhymes and of documents from the exact area of Chaucer’s upbringing in London, enables us to identify which of the various current types of London language Chaucer must have used. Interestingly enough, it turns out to be that used in Cambridge, Peterhouse 75.I of the Equatorie of the Planetis, which has been thought by some to be in Chaucer’s own hand (Samuels 1983).
4.2.4 A problematic tradition: the Piers Plowman texts
The Piers Plowman texts pose the most difficult problem of all. A Malvern origin, suggested by the distribution of the C-texts (4.1.4) is, perhaps rightly, not considered to be sufficiently authenticated by that evidence alone (this is at least implicit in Kane and Donaldson 1975, p. 215). But the Aand B-texts are the end-products of so much re-copying and translation that they can provide no guidance as to which of their relict forms are to be regarded as significant. Here, then, we have to look for quite different dialect evidence: Langland happens to alliterate on small grammatical words like those for the items ‘she’ and ‘are’, and these, combined with the phonological features of his alliteration, do in fact limit the dialect to south Worcestershire and corroborate a Malvern origin. From this one can conclude that the archetypal south Worcestershire layer in the B-manuscripts L and R (4.2.2), agreeing as it does with the language of the Malvern C-manuscripts, is likely to be authorial (Samuels 1985).
4.2.5 Chaucer’s metre
In recent decades the traditional view that Chaucer’s metre requires grammatical -e has been questioned (Southworth 1954, Robinson 1971). It is claimed that scribal representations of it are merely conventional and that it could not have been pronounced in Chaucer’s time. As an answer to this claim, the Hengwrt-Ellesmere scribe’s own spelling system should have sufficed, for no scribe could have internalised the complex rules governing the distinction between the Germanic strong and weak adjective if they were not also part of his inherited spoken language system. However, for those dissentients who still consider the evidence of this single scribe inadequate, our profiles for many non-Chaucerian scribes show the same usage as has to be postulated for Chaucer’s metre, and in their work, too, it cannot be dismissed as merely traditional since (a) it is obviously their own usage, not that of their exemplars, and (b) they all make the same distinction between a strong and weak adjective as the Hengwrt-Ellesmere scribe (Samuels 1972b).
4.3 Early Middle English
4.3.1 Extrapolation from later Middle English
The localisation of early Middle English texts properly requires a separate survey of all early Middle English material (cf. 5.1.2). But it is of interest to attempt to place them by extrapolating from the evidence of later Middle English, making allowance wherever necessary for the shifting of boundaries.
This is not as difficult as might be imagined. Before 1300, great orthographical differences are encountered, but the rate of linguistic change appears to be fairly constant; provided, therefore, one can distinguish accurately between stable and shifting lines, one can use the more stable ones to make a tentative placing, and then check how far this agrees with the expected shift of the other lines. For this reason we included, as secondary evidence only, the following six late-thirteenth-century manuscripts in our survey: (Oxford) Jesus College 29, Bodleian Library, Digby 86, (Cambridge) Trinity College B.14.39, British Library Cotton Otho C xiii (Laȝamon B), Cambridge University Library Gg.IV.27.2, and the Saints’ Lives in Bodleian Library Laud Misc. 108. The earliest of these is probably the Jesus College manuscript, and even this can be assigned fairly confidently to east Herefordshire, not far from the Worcestershire border. The main subsequent shifts that this presupposes are: the recession southwards of þey ‘though’, hi ‘they’, togadere ‘together’, þan ‘then’, and the replacement of these by þah (þauh), þei, ‘they’, togedere, þen; the recession northwards of þet ‘that’, serewe ‘sorrow’ and vacchen ‘fetch’; and the recession, both north and south, of rounding in beoþ ‘are’, hwuder ‘whither’ and stude ‘place’. Some of these shifts are borne out by the proportions of variants found in other texts from the area, but the most convincing feature of such a placing is that the postulated subsequent recessions are fairly evenly divided in direction, some northwards and others southwards.
4.3.2 Ancrene Riwle and Laȝamon A
If we move back still earlier in the thirteenth century, and attempt to localise the Nero manuscript of the Ancrene Riwle, we find that the same principles hold good. Its language, indeed, looks at first sight so similar to that of the Vernon manuscript, Bodleian Library Eng.poet.a.1 (e.g. hwon ‘when’, þauh ‘though’, seoruwe ‘sorrow’, þusund ‘thousand’) that one is tempted to place it in north Worcestershire as an anterior stage of the same language; but a number of other features point to a placing west-south-west of the Vernon manuscript, while the absence of yet other features precludes east Herefordshire. Admittedly, such a placing in west Worcestershire might be questioned on the grounds that we have now strayed too far from our original (roughly) synchronic plane for any pretensions to accuracy. But its validity is borne out in a remarkable way when we test the same method on Early Middle English texts or manuscripts that have local associations. The A-text of Laȝamon, which probably preserves the author’s language with only a slight degree of admixture, combines the features won ‘when’ (together with whan, whænne), marwen ‘morning’, and fæche ‘fetch’: no later texts we examined combine all these three, but it is probably significant that Areley Kings in north-west Worcestershire is just on the western fringe of our later whon-area, on the north-eastern fringe of the later marewe-area, and on the eastern fringe of the facche-area. Even assuming, as we probably must, that all these areas were slightly larger around 1200, Areley will still fit so neatly into the network of these and other boundaries as to confirm the use of the method on texts that have no local associations.
4.3.3 Eastern texts
The same methods may profitably be used for a number of early eastern texts. There is convincing evidence for localising a complex of six texts in west Norfolk (McIntosh 1976). They are: Havelok (Bodleian Library, Laud 108); the Havelok fragments (Cambridge University Library Add. 4407); scribe D of British Library, Cotton Cleopatra C vi (Ancrene Riwle), who also contributed to Cambridge, Trinity College B.1.45; The Bestiary (British Library, Arundel 292); Genesis and Exodus (Cambridge, Corpus Christi College 444); and various copies of cartularies and registers, especially those in British Library Add. 14847 and Cambridge University Library Ff.II.33. These texts show some striking differences in orthography from the later, mainly fifteenth-century, East Anglian evidence, e.g. w- beside rare qu- compared with later qw- and qwh-; -gt, -cht, -ht compared with later -cth, -th, -tht, -gth; and sal, scal, schal with no sign of the later typical xal. There are, however, many other diagnostic features which leave these localisations in no doubt. In addition, two other early eastern texts can be assigned with some confidence to south central Lincolnshire (British Library Add. 23983 and Oxford, Merton College 248), and even the much earlier Ormulum (Bodleian Library, Junius 1) fits convincingly in south Lincolnshire. A likely place of origin for this last, especially in view of the emphasis on its patron saints Peter and Paul, is the Arroaisian Abbey at Bourne (Parkes 1983).
4.4 Linguistic change
4.4.1 Recessive forms and relict areas
If the additional earlier texts mentioned in 4.3.1 are taken into account, the material of the survey covers as much as 150 years for a few areas, 125 or 100 years for the rest (cf. 1.1.1). With linguistic developments taking place during this period, we can naturally expect to find differences between earlier texts showing no change and later texts indicating a completed change. This factor has to be taken into account when interpreting a map, for what might at first sight appear to be a border-area (2.3.5) could, when the dates of the texts are considered, be more accurately interpreted as a clear-cut boundary that was in the course of shifting. An assessment of this situation enables us to observe the shrinking boundaries of recessive forms, e.g. the verbal prefix y-, or the ending -y(e), -i(e) of Class 2 Weak Verbs.
The same criterion has to be used when assessing whether an area is ‘relict’, i.e. whether it is, as a rural or otherwise isolated area, conservative because it has not yet been affected by the spread of new forms from surrounding centres of communication. Areas that could perhaps be defined thus are north Worcestershire and south-west Norfolk. In each case there are apparently conservative enclaves of features isolated from the main area of conservation, e.g. vuel, þulke, whuder (north Worcestershire), he ‘they’ and (more rarely) ȝhe ‘she’ (south-west Norfolk). In each case the isolation could be due to a swifter acceptance of innovations in a neighbouring cultural centre––Worcester in the west, Bury St. Edmunds in the east. Here, as before, one would need to take disparities of date into account as a possible contributory factor to the apparent unevenness of the distributions.
4.4.2 Correlation of items
Apart from noting recession in a given item from texts of different date, other indications of change may sometimes be gained by comparing maps of items which, though different, contain a similar phonic sequence. The distribution of the relict form dawes ‘days’ looks at first sight implausible, but when it is compared with the much wider distribution of (y-/a-)slawe(n) ‘slain’, it not only appears more likely in itself, but can be used to suggest the probable subsequent directions of recession in (y-/a-)slawe(n). Another possible comparison is of the distributions of wurk ‘work’, wurs ‘worse’ and fur- ‘for-’ (prefix): the narrow belts of these features occupy different areas, but they are fairly close, have a similar shape and for part of their course actually run parallel. While this could not be held to prove that wurs, wurk, fur- are relict forms, it might suggest that a wider belt once existed, in which there was a preference for the spelling -ur- (even though -or- is normally regarded as its equivalent after w-), but that this preference had become limited to different contexts in neighbouring areas. A further question then arises, whether this development could be regarded as a restricted but extreme form of the far more widespread change indicated in the -us, -ud (-ut) endings, or in aftur, which appears in a wide sweep from Cheshire and south Yorkshire southwards to the Isle of Wight. A comparison like the last may appear vague in isolation, but the phonetic implications of a large collection of such phenomena might be far-reaching.
4.4.3 Blend forms
The history of certain forms in ‘border-areas’ can often be deduced from a single map, by reference to the forms in adjacent areas. Some of these are obvious compromise forms (or ‘blends’) of comparatively recent origin: thus both hei and þy ‘they’ are to be found at various points on the boundary between þei and hy, and noiþer is found between noþer (nouþer) and neiþer. Others, though they can be derived quite regularly from some Old English or Old Norse etymon, evidently owe their form to the fact that it bridged the phonic gap between forms on each side: þaf ‘though’ (between þagh and þof), seyȝe ‘say’ (between segge and seye), and sych ‘such’ (often found between swych and such). A related but still commoner phenomenon is a belt of forms with unrounding of an originally rounded vowel, bordering on the area where rounding is still preserved: thus byþ, byn ‘are’ is found on the border of beoþ (buþ, beon, etc.) in Lancashire, Derbyshire, Hertfordshire, Surrey and Hampshire, and similarly––though in different areas–– stide bordering on stude, and ȝit bordering on ȝut.
This last word demonstrates how important it is to compile a map before attempting a phonological explanation of any form: Jordan explained ȝit as due to a raising of e to i between ȝ and dentals (1934, p. 54; 1974, p. 60), but the map suggests that this explanation is appropriate only to its occurrences in the north, not in the south. Similarly, the realisation that a text is from a border area may sometimes help to explain forms which might otherwise have been regarded as mere scribal oddities or confusions. For example, the forms wiþ þinne, wiþ þoute (wt þinne, wt þoute) occur near areas using biþinne, biþoute ‘within, without’: biþinne (itself presumably an older blend of OE binnan and wiðinnan) is often spelt by þynne, which suggests resyllabification due to mistaken identification with words containing the prefix bi-, and, as a compromise between by þynne and the commoner form wiþinne, we find the curious (but no doubt phonically significant) forms wiþ þinne (wt þynne, etc.).
Some of the more complex cases of such forms are of especial interest since they pose, in microcosm, the problem of how far a form may be said to descend from its etymon by mechanical phonetic change (‘sound-law’), and how far it is simply the result of its geographical position and environment. In Worcestershire and Herefordshire, we find a fairly well-defined area with euch(e) ‘each’, bordered to the north by vch(e) and to the south by ech(e); each of these three forms is said to descend from a different Old English form ––æghwilc, ylc and ælc respectively, but it is difficult to escape the conclusion that euch(e) owes its preservation ––and possibly even its selection in preference to other forms, and its phonetic development also––to the fact that it provided a link, both geographically and phonetically, between ech(e) and vch(e) (or their antecedent forms).
4.4.4 The growth of Standard English
The survey provides a frame of reference for isolating and classifying those types of language that are less obviously dialectal, and can thus cast light on the sources of the written standard that appears in the fifteenth century. The result is a typology of the kinds of language predominant in London from ca. 1430 onwards (Samuels 1963, 1972a, 1983). These show considerable differences which can be correlated with what is known about shifts in patterns of immigration to the capital: the mid-fourteenth-century texts show clear signs of East Anglian influences (e.g. werld and warld ‘world’, -ande for the present participle and even þerk ‘dark’), whereas after 1390 such forms tend to be ousted by others used elsewhere in the Midlands, especially if these latter were already current in the south. A further development of these new trends appears, in a perhaps misleadingly accumulated and sudden form, when the language of government documents changes, ca. 1430, from Latin and French to English (the so-called ‘Chancery Standard’). How far the language of these documents in the remainder of the fifteenth century can be regarded as a standard in the modern sense is a question that is much debated (Fisher 1977, Sandved 1981, Davis 1983, Fisher, Richardson and Fisher 1984). Its spread as a model for imitation is evidenced in a wide range of non-Chancery texts until well into the sixteenth century (Davis 1951-2, 1952 and 1954, Gómez Soliño 1984). The subject is re-examined in Benskin and Sandved (forthcoming). See the introduction to the second part of this volume, Index of Sources.
4.4.5 Historical interpretation of the data
The data of the linguistic profiles have led to the discovery of detailed systemic and analogical changes. An example is the appearance of a northern syntactic rule in Midland shape in an adjoining Midland area (McIntosh 1983). The northern rule requires that the present plural ending of the verb is -s except when a personal pronoun subject immediately precedes or follows the verb. If the verb is immediately next to a personal pronoun it has no inflexional ending. By an analogical development the adjoining Midland area (primarily north-east Leicestershire, Rutland, north Northamptonshire, north Huntingdonshire) shows a corresponding alternation of -eth and -e(n). Here the -eth plural originates simply in an equation of the Midland -eth singular with the northern -es for both singular and plural; it can have no connection, either geographically or historically, with the southern -eth plural.
Finally, there are the many distributions in the maps that can cast light on the history of English. The precise interpretation and significance of each may be open to debate, and such debate has no place in this Introduction; but the following items may be mentioned as of especial interest in this respect: these, those, she, they, them, their, such, which, each, any, are, is, then, than, though, against, again, yet, not, world, work, through, the present participle, the present endings of the verb, the y-prefix, at + infinitive, busy, call, church, dread (vb.), give, have, hither, hundred, I, old, six, star, thither, until, whether, worse, worship.
Chapter 5 PROSPECT
It would probably be agreed by most scholars of Middle English that, the longer they work, the more they are impressed by the vast quantity of the evidence that has survived, and also by the tantalising gaps they find in it. That, certainly, has been our experience, and we must therefore stress that, in spite of the volume of the evidence we now present, we cannot claim it to be more than a beginning. The process of achieving maximal accuracy and detail is not one that can be realised in this generation, and even the study of some of the wider implications will be a lengthy process. These latter will be considered first in the list of outstanding desiderata that follows.
5.1 Comparison with other stages of English
5.1.1 Modern dialects
It is often said that the next task after the completion of a modern dialect atlas should be to compare it with those for other regions, or with evidence for past stages of the language. The expectation of such comparisons is naturally much greater when an atlas of a previous stage of the language is produced. However, as was pointed out in 2.1.4, the choice of an ideal set of differentiating variables differs from region to region and from age to age. We cannot, therefore, expect linguistic atlases of either different areas or different periods to be strictly or wholly comparable (for example, in the Survey of English Dialects there is a concentration on farming terms, while in the Linguistic Survey of Scotland emphasis is put on the local names for flora and fauna: these just happened to provide the items for which the investigators knew they would find interesting local differentiations). Certainly, there are some items in both the Middle and the Modern English surveys that are comparable, and comparison of them, together with research into the reasons for changes, is one task that awaits. But for the rest, it will be largely a case of going back to the sources and searching for the mediaeval and modern counterparts of the items investigated in each survey. Some of the items in the modern surveys are so specialised that the likelihood of finding the required Middle English equivalents is small; but at least, for the remainder, there is now a greatly increased corpus of evidence from which to work.
5.1.2 Early Middle English
As was shown in 4.3, the later Middle English evidence itself can tell us much about the localisations of early Middle English texts, and the very process of extrapolation involves calculating what changes (such as the shifting of boundaries) are likely to have taken place between the two stages of Middle English. Nevertheless, however interesting such experimental extrapolations may be, they obviously cannot be made confidently until such time as an atlas of early Middle English dialects exists. For the south and Midlands at least, there survives sufficient textual material for a separate atlas, but for the reasons given in 2.1.4 and 5.1.1 a new questionnaire has to be devised, and that task is at present being undertaken at the Gayre Institute for Medieval English and Scottish Dialectology, University of Edinburgh. That is of course only the first stage, and much work lies ahead.
5.2 Widening the scope of enquiry
5.2.1 Word geography
In the present survey, the number of purely lexical items that could be included in the questionnaire was not large because their yield would have been too low for the immediate purpose of differentiating and localising texts. Lexical differentiators are often specialised (cf. 5.1.1), and there is no guarantee that they will occur frequently enough, if at all, in the texts available. But now that we have a large corpus of localised texts, it will be possible to take the exploration of word geography further than hitherto (McIntosh 1973; cf. Hudson 1983, and Appendix I, 3.9).
5.2.2 Middle Scots
The earlier view that Middle Scots was an artificial and uniform literary language has now been shown to be incorrect: just as in Middle English, the spelling habits of Middle Scots scribes show great variety (Aitken 1971). Although the evidence for Scots starts later than that for Middle English (there is little textual material before 1400), there is sufficient material, by way of both localised and unlocalised texts, for a survey of Scots-speaking areas south of the Tay, and probably sufficient for a survey of the north-east as well (McIntosh 1978). Indeed, the Gayre Institute, University of Edinburgh, is presently embarking on a study of such material. Even if some of the Middle Scots scribes prove difficult to localise, it will nevertheless be both useful and instructive to ‘fingerprint’ them by the construction of their linguistic profiles.
5.2.3 Graphetics
As already observed in 1.4.7, our knowledge of the graphetic characteristics of individual scribes can, if we care to extract and codify them, be incomparably more precise than that of the phonetic details of Middle English can ever be. A graphetic profile of each scribe would add an extra dimension to the information already available in the linguistic profile; it could possibly tell us more about patterns of regional distribution, and it would certainly tell us more about the scribes themselves (McIntosh 1975).
5.3 Late Middle English: the present survey
5.3.1 The search for further materials
The coverage we have achieved is uneven, and far from ideal. For certain areas, there is a decided scarcity of localised documents (2.3.2). The texts placed in such areas give a convincing fit, but corroboration is desirable. That corroboration could come either from the discovery of fresh localised documents (Benskin 1977), or by testing the matrix with further unlocalised material; preferably both methods should be applied.
5.3.2 The need to refine the results
Just as the coverage achieved has been uneven, so, perforce, has the quality of the materials used. For some areas (e.g. Cornwall) we have had no option but to use material that is mixed (cf. Wakelin 1981). Such texts were included because they were judged to contain information the value of which outweighed the danger of minor mixtures. Since it would be arbitrary in these cases to select some forms but exclude others, certain extraneous variants inevitably appear on the maps. The principle adopted here accords with our aim of increasing the overall evidence, but there is no doubt that such problems remain for treatment by future scholars. If they can find some trustworthy way of isolating only those forms that belong to the extraneous stratum, they will thereby contribute to the refinement of the mapped data and, possibly, to their simplification.
5.3.3 Concluding remarks
We reiterate: even on late Middle English, work has only begun. Like all exploratory scholarship, it is provisional, and subject to revision when new information is discovered. Essentially, we claim to have presented a large corpus of literary texts and to have localised them (in some cases more provisionally than in others). But this corpus is capable of answering far more questions than any previous one, and there are many further questions waiting to be asked. Since these new questions will not necessarily be restricted to the kinds enumerated above, the volume of work that remains will occupy many research programmes, both large and small, for the foreseeable future.
Appendix 1
Translation between dialects in Middle English
Translation has already been discussed in 1.3.2–3 and elsewhere in this Introduction, and some fairly detailed commentary appears in the account of what we have called ‘PseudoMischsprachen’ (3.3). In 3.3.2–4, Progressively translated texts, we noted that a scribe may drift into translation as he becomes more familiar with the language of his exemplar, or at any rate as he settles down to the particular job in hand. Such ‘working-in’ is often reflected also by the state of the script: proper fluency and consistency are not achieved until a few, sometimes several folios, have been completed. We have also held that the dialectal state of verse texts commonly justifies the assumption of a scribal ‘diglossia’, and indicates translation as a policy that was deliberate and consequently maintained (3.3.7).
Here, however, we have little to add concerning translation effected as a deliberate policy. Rather, we shall consider the case that particular modes of copying and of script may themselves conduce towards translation as a normal outcome of scribal activity. We shall argue that any scribe who had an active command of Middle English as his habitual written language––in other words, who had learned how to write for himself, and not merely to replicate letter-shapes and sequences from an exemplar ––was more likely than not to impose his own written language on a text that he copied. These matters, it appears, are closely bound up with the larger history of Middle English as a written language, and probably also with the development of cursive script; the first part of this Appendix therefore comprises a historical sketch from early Middle English to the 15th century. There then follows a short critique of some previous assumptions about translations between dialects, and we conclude with an estimate of the overall linguistic character of the translated corpus.
1. Translation: some Middle English perspectives
1.1 Translation between dialects is by no means unknown in the early Middle English period, and some texts, designed for reading aloud to local audiences, show signs of having been translated as a matter of policy from the outset. Nevertheless, it is our impression that translation is a commoner practice in later Middle English, in so far as we can assess relative proportions of linguistically homogeneous outputs known from each period. Until such time as the linguistic character of the early Middle English corpus has been examined as thoroughly as that of the later writings, this will have to remain an impression merely; but it seems worth enquiring into the circumstances of the fairly general shift in copying practice that this implies.
1.2 Firstly, the proportion of twelfth- and thirteenth-century output comprised by texts in English was small: Latin and AngloNorman, even outside administrative writings, accounted for much the greater part. There were probably few scribes who were employed solely in the copying of English texts, and the habits of the majority were formed in the writing of Anglo-Norman and Latin. Writing was during this period an essentially clerical accomplishment: lay literacy was uncommon, and this of itself indicates Latin as the familiar language of most people who were literate. The conventions appropriate to the writing of Latin are, of course, very different from those associated with copying texts in a language that, as a written language, is dialectally very diverse. In copying Latin text there is very little scope for departure from the precise form of the original. There are relatively few alternative spellings, and even choice as to abbreviation is largely determined by the mode of script: heavily contracted Latin belongs mostly to cursive and informal or debased script, whereas formal non-cursive scripts admit relatively little abbreviation.
1.3 Copying Latin demands that in all essentials the spelling of the copy-text be replicated. Any departure from it is likely to constitute a mistake, and in a highly inflected language even a single spelling mistake is very likely to make nonsense of the text. We may therefore assume that most scribes were at least trained as letter-by-letter copyists and, in so far as they copied vernacular texts at all, they were likely to transfer the Latin habit. Although it cannot be proven, and the extant corpus is so small a proportion of the whole output as to render the survival of orthographically identical copies unlikely in the extreme, we may suspect nevertheless that scribes of vernacular texts were predisposed towards literatim-copying much more than in later Middle English times. Some evidence for this is provided by the linguistic discrepancies between different literary texts copied by a single scribe but from presumably diverse exemplars: Celia Sisam’s study of the Lambeth Homilies provides a particularly thorough demonstration of this (Sisam 1951), and similar interference patterns could be cited from many other manuscripts.
1.4 The resurgence of English as a written language, which on the evidence of the surviving manuscripts may be dated from about the middle of the fourteenth century, must of itself have been partly responsible for a change in copying habits. To begin with, the more English manuscripts that were produced, the more likely it is that copying texts became the habitual occupation of a large number of scribes. Secondly, there was for English no written standard acknowledged beyond initially the scriptorium, and later the region, until well into the fifteenth century. There was no one written dialect which could be identified as the embodiment of written English itself, and in the copying of English literary texts, acquaintance with diverse dialects was the experience of perhaps even a majority of scribes. Since, for most literary purposes, no one written dialect had more prestige than any other, scribes generally were under no pressure to preserve the spelling of an exemplar in place of their own spontaneous forms. Part of the impulse to translate must have depended on the association of particular spellings with particular forms in the spoken language: the alteration of, say, mekell to moch might be construed as a way merely of making a text intelligible to its intended reader at first glance, rather than leaving him to translate on sight––an alteration which, in texts designed for reading aloud in public, might be of great practical advantage. The part of the spoken language in the production of translated texts is not, however, confined to deliberate conversion of this sort, and the process we have suggested may for many scribes be largely unconscious: for some account of ‘dictation via the mind’s ear’, see 3.3.2 above.
1.5 So far, therefore, the existence of English in a great variety of orthographies, and the upsurge of a lay literacy that was to a large extent independent of Latin and hence of the mechanics associated with copying Latin text, may be invoked as reasons for an increasingly common practice of translation between Middle English dialects.
1.6 A third reason has received little if any attention hitherto. It is surely no accident that the habit of translation spreads with the development of cursive bookhands. In non-cursive script, letterby-letter copying is possible in a way that cursive writing scarcely permits: if the flow of cursive writing is to be maintained, the unit of copying must be larger than a single letter, and can scarcely be smaller than the word. A copyist working at speed takes in a whole phrase or more at a time, and reproduces all of it before moving his eyes away from his own writing and back to the exemplar. Accordingly, he is much more likely to work to his own (perhaps silent) dictation than to reproduce the visual symbols which lie behind the sequence of words that he now holds in his mind. With Latin texts such a practice affects the spelling of the copy hardly at all, just because the spelling of Latin is largely fixed; but in a language that admits dialectal variation at the written level such practice leads almost inevitably to translation between dialects. This is not to say that a copyist whose script is non-cursive cannot produce a consistently translated text, but that the script by itself, unlike cursive writing, provides him with no inbuilt motive for doing so. From such limited study as we have made of correlations between language and script, it appears that in later Middle English manuscripts non-cursive writing is associated with linguistically heterogeneous copies––Mischsprachen ––much more commonly than are cursive scripts. The only large class of textura manuscripts that runs counter––and it is a very large class indeed––comprises the writings of Lollardy: in these, the language is predictable often from a mere glance at the hand, and it is nearly always some internally consistent sub-variety of Central Midland Standard. (Cf. Samuels 1963, pp. 84–5.) Cursive script and translation between dialects go together in the history of Middle English, and this is not merely another way of observing that the bulk of the Middle English output in any case belongs to the later part of the period, when cursive bookhands had already become well established. What we have to consider here is the relative proportions of cursively written-texts and the relative proportions of translated texts at different stages in the history of Middle English.
1.7 Cursive bookhand proper, as opposed to cursive business hand, had come into being by the middle of the thirteenth century. Books written in cursive script are known from before this time, but for book production during the early Middle English period, cursive had yet to be established as a regular mode. Moreover, the cursive literary output was confined in the main to Latin texts, particularly the ever-expanding theological commentaries which had themselves given powerful impetus to the development of cursive and heavily contracted bookhand; and it was not until the days of Lollardy that theological argument was conducted in English prose. Proportionately, very little of the early Middle English output is in cursive script.
1.8 In contrast, for later Middle English, the period from ca. 1350, cursive bookhands are the norm. Of these, M.B. Parkes has written:
The script settled down into the kind of handwriting which could be used not only for writing documents but also as a cheap bookhand ... By the end of the fourteenth century there was demand from all classes of patrons for cheap books, and the appearance in inventories of volumes of romances, valued often at only a shilling or two each, would seem to indicate some form of book production designed to meet this demand. I venture to suggest that the appearance of this script in many of the manuscripts containing romances and other vernacular texts in the fourteenth century and later may well be connected with this form of book production.
