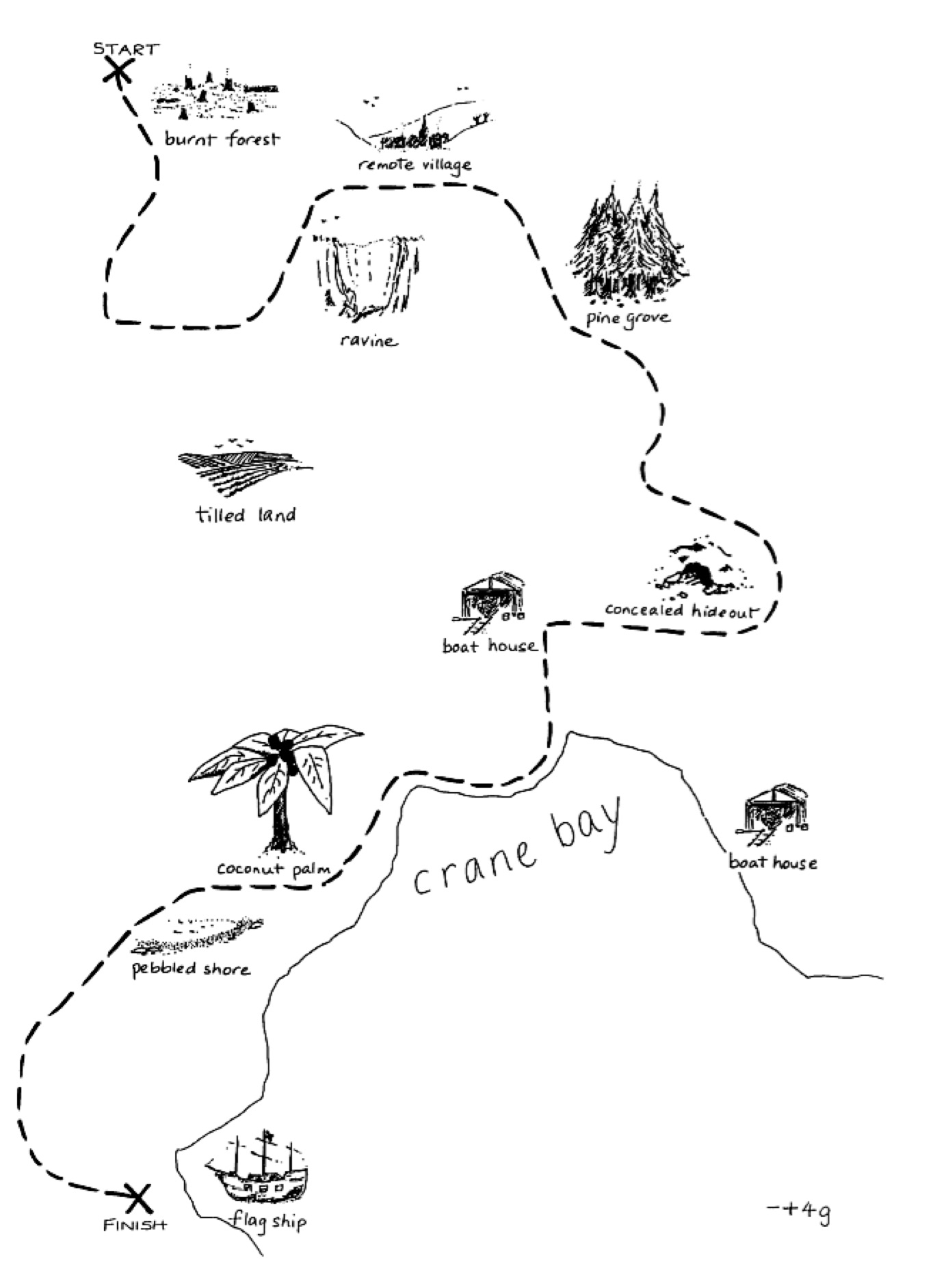
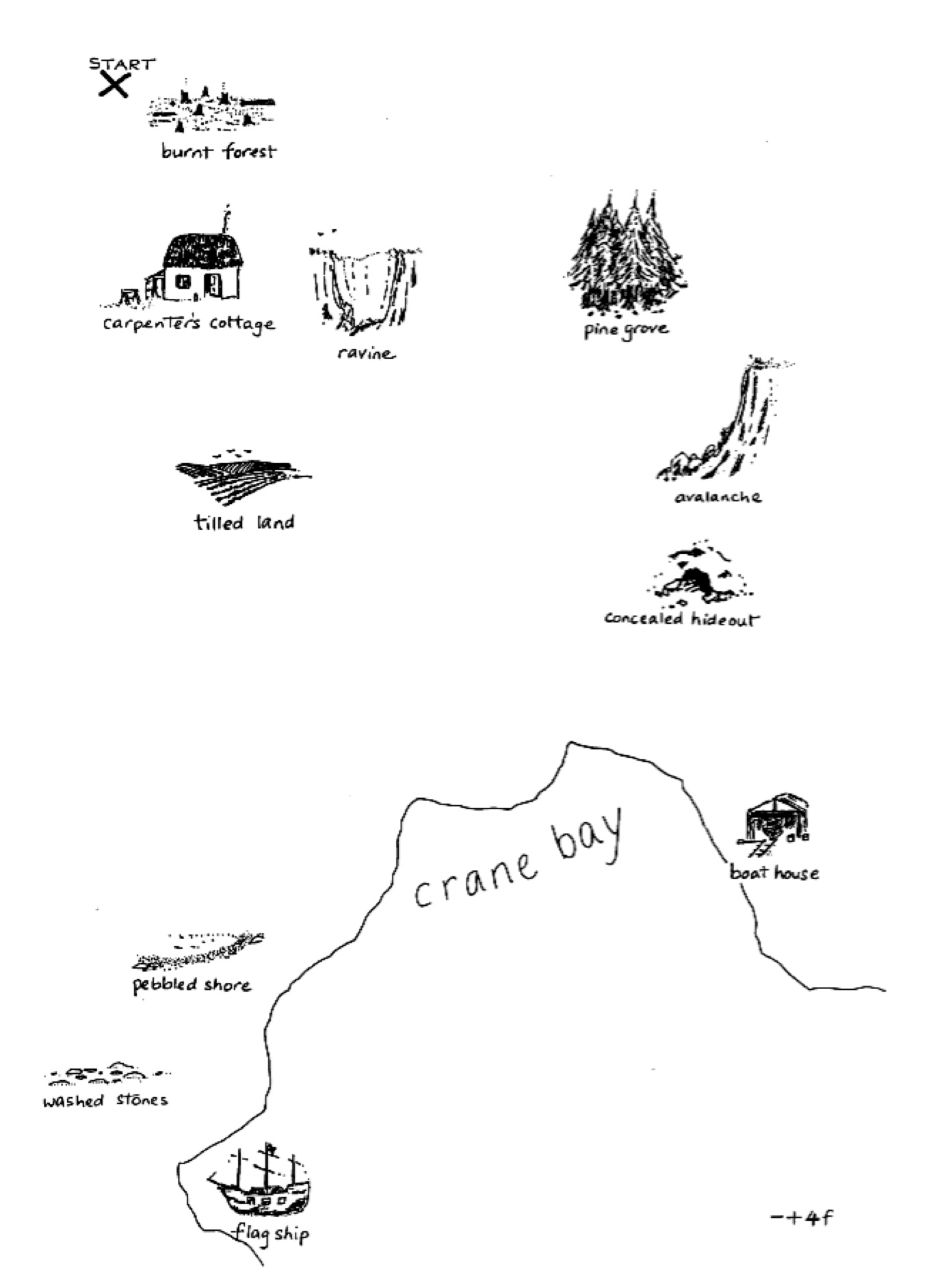
The dialogue corpus we'll be using is ideal for an analysis of referential choice because the language across dialogues is unscripted (hence, natural conversation) but also structurally similar (hence, easier to compare). Each dialogue consists of a conversation between a pair of participants, each with a map in front of them. The participant in the "guide" role has a path indicated on their map, and they are trying to convey to the "follower" how to replicate that path on their map. They cannot see each other's maps and the maps are slightly different. See the sample pair of guide/follower maps at the bottom of this page.
Here is a sample dialogue between two participants working with the maps below:
For LEL2B, your task is to annotate the utterances in the dialogues in order to permit an analysis of the referring expressions speakers use. To do this, you'll work with your small group to decide how many files to annotate, to divide up the work, to make decisions about what to include/exclude, and eventually to combine your annotations with those of the other groups (individual annotations due Friday 15 November). You will then conduct further analyses on the entire dataset for your final research report (individual final reports due as 'Assessment #3' on Thursday 5 December)
The utterances vary in a few ways, and these properties are indicated in the files themselves:
The information above, and more, is available as part of the project description: link TBA .
KEY POINT: Publicly available corpora provide a useful resource for testing pragmatic theories and other linguistic generalisations.